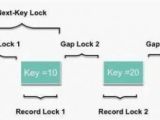
 摘要:最近项目中某个模块稳定复现MySQL死锁问题,本文记录死锁的发生原因以及解决办法。测试环境:[root@node232 ~]# cat /etc/redhat-releaseCentOS release 6.9 (Final)[root@node232 ~]# uname -aLinux node232 2.6.32-696.el6.x86_64 #1 SMP Tue Mar 21 19:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux[root@node232 ~]# mysql -e "\s"--------------mysql V
摘要:最近项目中某个模块稳定复现MySQL死锁问题,本文记录死锁的发生原因以及解决办法。测试环境:[root@node232 ~]# cat /etc/redhat-releaseCentOS release 6.9 (Final)[root@node232 ~]# uname -aLinux node232 2.6.32-696.el6.x86_64 #1 SMP Tue Mar 21 19:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux[root@node232 ~]# mysql -e "\s"--------------mysql V2021年07月24日
 MySQL高级DBA之第六讲-死锁案例分析
MySQL高级DBA之第六讲-死锁案例分析
摘要:最近项目中某个模块稳定复现MySQL死锁问题,本文记录死锁的发生原因以及解决办法。测试环境:[root@node232 ~]# cat /etc/redhat-releaseCentOS release 6.9 (Final)[root@node232 ~]# uname -aLinux node232 2.6.32-696.el6.x86_64 #1 SMP Tue Mar 21 19:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux[root@node232 ~]# mysql -e "\s"--------------mysql V分类:DataBase
2021年07月23日
Kubernetes 1.21.2部署dashboard 2.3.1
 摘要:Kubernetes 1.21.2部署dashboard 2.3.1Kubernetes 版本: 1.21.2Dashboard 版本 : v2.3.1检查dashboard版本与kubernetes版本兼容性:https://github.com/kubernetes/dashboard/releases部署Dashboard需要提取的镜像:ImagesKubernetes Dashboard kubernetesui/dashboard:v2.3.1Metrics Scraper kubernetesui/metrics-scraper:v1.0.6kubectl apply -f https://raw.githubuserco
摘要:Kubernetes 1.21.2部署dashboard 2.3.1Kubernetes 版本: 1.21.2Dashboard 版本 : v2.3.1检查dashboard版本与kubernetes版本兼容性:https://github.com/kubernetes/dashboard/releases部署Dashboard需要提取的镜像:ImagesKubernetes Dashboard kubernetesui/dashboard:v2.3.1Metrics Scraper kubernetesui/metrics-scraper:v1.0.6kubectl apply -f https://raw.githubuserco分类:系统管理
2021年07月23日
使用kube-prometheus部署k8s-1.21.2监控(最新版)
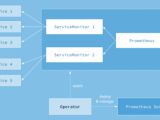 摘要:kubernetes的最新版本已经到了1.20.x,利用假期时间搭建了最新的k8s v1.20.2版本,截止我整理此文为止,发现官方最新的release已经更新到了v1.21.2。1、概述1.1 在k8s中部署Prometheus监控的方法通常在k8s中部署prometheus监控可以采取的方法有以下三种· 通过yaml手动部署 (本文的部署方式)· operator部署
摘要:kubernetes的最新版本已经到了1.20.x,利用假期时间搭建了最新的k8s v1.20.2版本,截止我整理此文为止,发现官方最新的release已经更新到了v1.21.2。1、概述1.1 在k8s中部署Prometheus监控的方法通常在k8s中部署prometheus监控可以采取的方法有以下三种· 通过yaml手动部署 (本文的部署方式)· operator部署分类:系统管理
2021年07月11日
MySQL5.7-OCP-配置组复制之多主模式(Multi-Primary Mode)
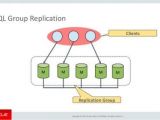 摘要:Configuring Group Replication in Multi-Primary Mode1.接上面单主模式的配置,将4台实例全部停止[root@node232 group_Replication]#mysqld_multi --defaults-file=/server/shell_scripts/group_Replication/grouprep.cnf stop 1-4或者:[root@node232 group_Replication]# mysqladmin -uroot -p -h127.0.0.1 -P3311 shutdown[root@node232 group_Replication]# mysqlad
摘要:Configuring Group Replication in Multi-Primary Mode1.接上面单主模式的配置,将4台实例全部停止[root@node232 group_Replication]#mysqld_multi --defaults-file=/server/shell_scripts/group_Replication/grouprep.cnf stop 1-4或者:[root@node232 group_Replication]# mysqladmin -uroot -p -h127.0.0.1 -P3311 shutdown[root@node232 group_Replication]# mysqlad分类:DataBase
2021年07月11日
MySQL5.7-OCP-配置组复制之单主模式(Single-Primary Mode)
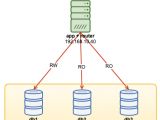 摘要:Configuring Group Replication in Single-Primary Mode1.查看停止当前的mysql服务:#service mysqld stop2.查看grouprep.cnf启动配置文件:[mysqld1]# Server configurationdatadir=/var/lib/mysql1port=3311socket=/var/lib/mysql1/mysql.sock# General Replication configurationserver-id=1user=mysqlbinlog-format=ROWbinlog-checksum=NONElog-bin=mysql1-binrelay-log=my
摘要:Configuring Group Replication in Single-Primary Mode1.查看停止当前的mysql服务:#service mysqld stop2.查看grouprep.cnf启动配置文件:[mysqld1]# Server configurationdatadir=/var/lib/mysql1port=3311socket=/var/lib/mysql1/mysql.sock# General Replication configurationserver-id=1user=mysqlbinlog-format=ROWbinlog-checksum=NONElog-bin=mysql1-binrelay-log=my分类:DataBase
2021年07月10日
MySQL5.7-OCP-配置主从复制(Configuring Replication)
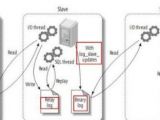 摘要:通过配置多实现来做来实验的平台,在一台服务器上,配置4个MySQL实例1.将现在的MySQL服务器停止[root@node232 ~]# service mysqld stopShutting down MySQL.. SUCCESS!2.查看多实例repl.cnf文件 [root@node232 replication]# cat repl.cnf[mysqld1]datadir=/var/lib/mysql1port=3311socket=/var/lib/mysql1/mysql.sockserver-id=1user=mysqllog-bin=mysql1-binrelay-log=m
摘要:通过配置多实现来做来实验的平台,在一台服务器上,配置4个MySQL实例1.将现在的MySQL服务器停止[root@node232 ~]# service mysqld stopShutting down MySQL.. SUCCESS!2.查看多实例repl.cnf文件 [root@node232 replication]# cat repl.cnf[mysqld1]datadir=/var/lib/mysql1port=3311socket=/var/lib/mysql1/mysql.sockserver-id=1user=mysqllog-bin=mysql1-binrelay-log=m分类:DataBase
2021年07月04日
MySQL OCP5.7-使用索引提高查询性能
 摘要:1.查询employees库的titles表:root@localhost[(none)]>use employees;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedroot@localhost[employees]>select emp_no,title from titles where title='Manager' AND to_date>NOW();+--------+---------+| emp_no | ti
摘要:1.查询employees库的titles表:root@localhost[(none)]>use employees;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedroot@localhost[employees]>select emp_no,title from titles where title='Manager' AND to_date>NOW();+--------+---------+| emp_no | ti分类:DataBase
2021年07月04日
MySQL OCP5.7-确定导致性能较慢的原因(锁等待)
 摘要:1.打个两个终端T1和T2T1:[root@node232 ~]# mysqlWelcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 4Server version: 5.7.18-log MySQL Community Server (GPL)Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other
摘要:1.打个两个终端T1和T2T1:[root@node232 ~]# mysqlWelcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 4Server version: 5.7.18-log MySQL Community Server (GPL)Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other分类:DataBase
2021年07月01日
MySQL OCP5.7之启用SSL以实现安全连接
 摘要:查看服务器是否开启SSL:root@localhost[(none)]>show variables like 'have_ssl' -> ;+---------------+----------+| Variable_name | Value |+---------------+----------+| have_ssl | DISABLED | #表示没有开启SSL+---------------+----------+1 row in set (0.00 sec)通过mysql_ssl_rsa_s
摘要:查看服务器是否开启SSL:root@localhost[(none)]>show variables like 'have_ssl' -> ;+---------------+----------+| Variable_name | Value |+---------------+----------+| have_ssl | DISABLED | #表示没有开启SSL+---------------+----------+1 row in set (0.00 sec)通过mysql_ssl_rsa_s分类:DataBase
2021年06月26日
MySQL InnoDB存储引擎DML一定是行锁吗?
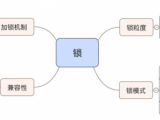 摘要:在一般开发或DBA看来,MySQL InnoDB存储引擎的锁粒度一定是行锁,然后思想就根深蒂固了。今天要跟大家分享行锁与表锁的条件创建表并插入数据:root@localhost[test]>create table test (id int primary key,name varchar(20) not null default '0');Query OK, 0 rows affected (0.02 sec)root@localhost[test]>insert into test (id,name) values (1,'rsc'),(2,'gmy');Qu
摘要:在一般开发或DBA看来,MySQL InnoDB存储引擎的锁粒度一定是行锁,然后思想就根深蒂固了。今天要跟大家分享行锁与表锁的条件创建表并插入数据:root@localhost[test]>create table test (id int primary key,name varchar(20) not null default '0');Query OK, 0 rows affected (0.02 sec)root@localhost[test]>insert into test (id,name) values (1,'rsc'),(2,'gmy');Qu分类:DataBase
2021年06月20日
MySQL OCP5.7之配置多实例数据库
 摘要:配置mysql多实例一、配置单独一个实例:1.创建目录:#mkdir /mysql/data/ -p#chown mysql:mysql /mysql2.初始化数据目录:[root@node232 ~]# mysqld --no-defaults --initialize --user=mysql --datadir=/mysql/data2021-06-20T00:37:05.282207Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server optio
摘要:配置mysql多实例一、配置单独一个实例:1.创建目录:#mkdir /mysql/data/ -p#chown mysql:mysql /mysql2.初始化数据目录:[root@node232 ~]# mysqld --no-defaults --initialize --user=mysql --datadir=/mysql/data2021-06-20T00:37:05.282207Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server optio分类:DataBase
2021年06月09日
MySQL8.0.25-基于GTID复制配置
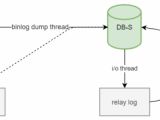 摘要:原理图:基于GTID的流程图:GTID 相比binlog复制的优势如果传统复制一主两从的情况下.如果了两个从库数据并不是同步的.那么在主库挂了以后重新指向最新数据的从库为主库的时候就会出现数据不一致的情况.因为之前两个数据库中的数据是从master中同步的.而重新指向的新的从库为主库的情况下数据较全的从库并不会将数据同步到新的2号从库中.就会导致数据差异.需要人工干预来找到bi
摘要:原理图:基于GTID的流程图:GTID 相比binlog复制的优势如果传统复制一主两从的情况下.如果了两个从库数据并不是同步的.那么在主库挂了以后重新指向最新数据的从库为主库的时候就会出现数据不一致的情况.因为之前两个数据库中的数据是从master中同步的.而重新指向的新的从库为主库的情况下数据较全的从库并不会将数据同步到新的2号从库中.就会导致数据差异.需要人工干预来找到bi分类:DataBase
2021年05月12日
用一次你就会爱上它,MySQL在线DDL工具gh-ost
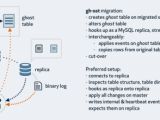 摘要:生产环境中我们都会遇到在线修改MySQL表结构的事,如果是小表(10W-100W)左右的数据量,还比较好处理,如果是订单或日志类的在线表,就会比较麻烦,在没有这个工具以前,只能等到数据库访问底峰或凌晨来处理。还好有gh-ost这个工具,简直是DBA的福星,下面就详细介绍以下这款神器。简介: gh-ost基于 golang 语言,是 github 开源的一个 DDL 工具,是
摘要:生产环境中我们都会遇到在线修改MySQL表结构的事,如果是小表(10W-100W)左右的数据量,还比较好处理,如果是订单或日志类的在线表,就会比较麻烦,在没有这个工具以前,只能等到数据库访问底峰或凌晨来处理。还好有gh-ost这个工具,简直是DBA的福星,下面就详细介绍以下这款神器。简介: gh-ost基于 golang 语言,是 github 开源的一个 DDL 工具,是分类:DataBase
2021年04月30日
Redis主从+Sentinel+Haproxy哨兵集群-自动选master部署
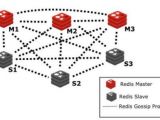 摘要:配置前题:redis主从以及哨兵模式已配置完成哨兵环境:IP 主机名 类型172.16.1.200 node200 master172.16.1.201 node201 slave172.16.1.202 node202 slave 1、安装Haprox
摘要:配置前题:redis主从以及哨兵模式已配置完成哨兵环境:IP 主机名 类型172.16.1.200 node200 master172.16.1.201 node201 slave172.16.1.202 node202 slave 1、安装Haprox分类:系统管理
2021年04月30日
Redis-一主二从三哨兵高可用模式部署
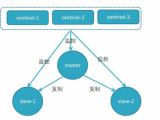 摘要:操作系统环境:[root@node200 ~]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node200 ~]# uname -aLinux node200 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux这里使用三台服务器,每台服务器上开启一个redis-server和redis-sentinel服务,redis-server端口为6379,redis-sentinel的端口为26379拓扑主机
摘要:操作系统环境:[root@node200 ~]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node200 ~]# uname -aLinux node200 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux这里使用三台服务器,每台服务器上开启一个redis-server和redis-sentinel服务,redis-server端口为6379,redis-sentinel的端口为26379拓扑主机分类:系统管理
2021年04月22日
MongoDB-单节点升级为副本集高可用集群配置案例
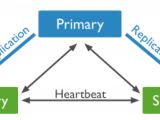 摘要:项目背景由于历史原因,我们有一个作数据同步的业务,生产环境中MongoDB使用的是单节点。但随着业务增长,考虑到这个同步业务的重要性,避免由于单节点故障造成业务停止,所以需要升级为副本集保证高可用。副本集架构下面这架构图是这篇文章需要实现的MongoDB副本集高可用架构:升级架构前注意事项在生产环境中,做单节点升级到集群前,一定要先备份好mongodb的所有数据,避免操
摘要:项目背景由于历史原因,我们有一个作数据同步的业务,生产环境中MongoDB使用的是单节点。但随着业务增长,考虑到这个同步业务的重要性,避免由于单节点故障造成业务停止,所以需要升级为副本集保证高可用。副本集架构下面这架构图是这篇文章需要实现的MongoDB副本集高可用架构:升级架构前注意事项在生产环境中,做单节点升级到集群前,一定要先备份好mongodb的所有数据,避免操分类:系统管理
2021年04月22日
周彦伟谈-DBA精神:责任心、服务心、沟通心、学习心、进取心和分享心
 摘要:DBA精神是责任心的体现维护数据库数据的安全和完整是管理员的首要责任。在管理数据库的过程中,作为一个DBA,要把数据库看做自己的财产、自己的儿女、自己身体的一部分。此种职责,需要你像呵护自己眼睛一样去照顾你所维护的数据库。时刻去想,有没有做应该有的备份,有没加应该有的监控,有没有做必须的安全权限限制。一旦出问题,有没有第一时间去分析和解决问题,这就像你的
摘要:DBA精神是责任心的体现维护数据库数据的安全和完整是管理员的首要责任。在管理数据库的过程中,作为一个DBA,要把数据库看做自己的财产、自己的儿女、自己身体的一部分。此种职责,需要你像呵护自己眼睛一样去照顾你所维护的数据库。时刻去想,有没有做应该有的备份,有没加应该有的监控,有没有做必须的安全权限限制。一旦出问题,有没有第一时间去分析和解决问题,这就像你的分类:Linux世界
2021年04月20日
民用水电,莲塘一中,七中,洪州学校旁边,房东直租,免中介费,精装修,复式loft 近地铁3号线沥山站 拎包入住 诚心出租 租金好商量
 摘要:房源概况:交通便利 现代风格简装修房子出租房东直租,免中介费,可以做饭,南昌县全新现房loft温馨复式公寓2室2厅1卫 ,距离3号线地铁口沥山站700多米,楼下就有公交站点: 小蓝一路东口,途径线路有179路长班,218路, 房间配置:热水器,空调,洗衣机,电视,冰箱,大衣柜,餐桌,凳子,沙发,两张床,抽油烟机等设施齐全。楼层适中有电梯,采光视野好,环境安静。现征爱干净,不
摘要:房源概况:交通便利 现代风格简装修房子出租房东直租,免中介费,可以做饭,南昌县全新现房loft温馨复式公寓2室2厅1卫 ,距离3号线地铁口沥山站700多米,楼下就有公交站点: 小蓝一路东口,途径线路有179路长班,218路, 房间配置:热水器,空调,洗衣机,电视,冰箱,大衣柜,餐桌,凳子,沙发,两张床,抽油烟机等设施齐全。楼层适中有电梯,采光视野好,环境安静。现征爱干净,不分类:Linux世界
2021年04月19日
MongoDB副本集强制其中一个节点为主库并重做副本集集群案例分享
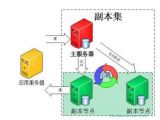 摘要:配置环境:CentOS:[root@node252 lib]# uname -aLinux node252 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux[root@node252 lib]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node252 lib]# rpm -qa | grep mongomongodb-org-mongos-4.0.18-1.el7.x86_64mongodb-org-server-4.0.18-1.el7.x86_64mongodb-o
摘要:配置环境:CentOS:[root@node252 lib]# uname -aLinux node252 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux[root@node252 lib]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node252 lib]# rpm -qa | grep mongomongodb-org-mongos-4.0.18-1.el7.x86_64mongodb-org-server-4.0.18-1.el7.x86_64mongodb-o分类:系统管理
2021年04月19日
python连接mongodb副本集-插入测试数据脚本
摘要:[root@node250 python_scripts]# cat Mongodb_insert_data.py#!/usr/bin/python# -*- coding: utf-8 -*-import pymongofrom pymongo import MongoClientfrom pymongo import ReadPreferenceimport timeimport argparse# 定义执行时长装饰器函数def warps(*args): def deco(func): def _deco(*args, **kwargs): &n
分类:Python
关于我

Linux&MySQL数据库运维服务项目:
1.MySQL运维外包服务
2.MySQL高可用架构部署与调优
3.MySQL分库分表中间件部署与调优
4.MySQL数据库恢复及紧急救援服务
-> MySQL 误操作drop table/truncate table/drop database恢复
->MySQL 文件被误删除
->MySQL 数据库IB文件损坏等
->MySQL 备份损坏等
->MySQL 性能问题或疑难问题排查
->Linux 文件系统损坏、磁盘损坏等
5.MySQL数据库监控与报警
6.MySQL InnoDB Cluster集群
7.MySQL CDC数据同步工具
8.MySQL远程安装
9.VPN翻墙架设
10.Linux系统安全、监控、调优、应急故障处理
11.LANMPT网站平台环境安装配置,性能优化
12.详细报价以及其它服务内容请访问:www.ywsos.com
13、RHCE证书,CCNA证书,MySQL OCP,Oracle OCP证书信息查看
14、官方文档:
ORACLE_11G
MySQL_5.7
MySQL_8.0
PostgreSQL-13.1-CN
最火博文
 500台服务器搬迁,不容易啊
500台服务器搬迁,不容易啊- no active checks on server [127.0.0.1:10051]: host [zabbix.linuxidc.com] not found
- Docker FAQ FATA[0000] Error mounting devices cgroup: mountpoint for devices not found
- 查看mysql5.5 cmake安装时的编译参数
- 查看apache已安装的编译参数
- sudo权限集中管理与用户行为审计
- for和while常用方法
- /var/lock/subsys目录的作用
- Linux,25 岁生日快乐!
- MySQL,Oracle和PostgreSQL数据库体系架构详解
- 二进制包安装mysql5.5.32(免编译)
- Apache中RewriteRule和RewriteCond规则参数的详细介绍-域名跳转
- MySQL Proxy读写分离配置
- 全面解析Django的静态文件路径设置statics(settings.py)
- 关于世界上最伟大的Linux系统25个真相
最新评论
- [instance]
sql-mode = "STRICT_TRANS_TABLES"直接配置文件里加上这个试过了市可以的。
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- New topology could not be saved: Failed to parse topology file: yaml: unmarshal errors:
line 18: field instance.sql_mode not found in type spec.TiDBSpec
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- 大哥,5.1的esxi还能再共享一下吗?
- 匿名 @ VMware ESXi定制版(OEM ISO)资源下载(更新中)
- 没效果啊
- 匿名 @ 使用tab自动补全mysql命令
- 666
- 匿名 @ 500台服务器搬迁,不容易啊
- 111
- 匿名 @ 500台服务器搬迁,不容易啊
- 很好,
- ty-hongjy @ Flexviews-MySQL物化视图
- firewalld的防火墙的有吗?
- 匿名 @ Shadowsocks如何设置多外网IP