 摘要:MySQL 8.0.30引入了“生成的不可见主键”(GIPK)功能。本博客介绍了此功能,讨论了其局限性和限制,并描述了备份和恢复操作如何使用此功能。让我们开始吧! 背景InnoDB存储引擎包含一个称为隐式主键的内部功能。此功能会在生成的名为DB_ROW_ID的列上自动生成名为GEN_CLUST_index的隐藏聚集索引。隐式主键是在创建没有Primary Key或UNIQUE Key的表时生成的,其中所有键列都
摘要:MySQL 8.0.30引入了“生成的不可见主键”(GIPK)功能。本博客介绍了此功能,讨论了其局限性和限制,并描述了备份和恢复操作如何使用此功能。让我们开始吧! 背景InnoDB存储引擎包含一个称为隐式主键的内部功能。此功能会在生成的名为DB_ROW_ID的列上自动生成名为GEN_CLUST_index的隐藏聚集索引。隐式主键是在创建没有Primary Key或UNIQUE Key的表时生成的,其中所有键列都2023年09月15日
 MySQL 8.0.30 新特性 不可见主键
MySQL 8.0.30 新特性 不可见主键
摘要:MySQL 8.0.30引入了“生成的不可见主键”(GIPK)功能。本博客介绍了此功能,讨论了其局限性和限制,并描述了备份和恢复操作如何使用此功能。让我们开始吧! 背景InnoDB存储引擎包含一个称为隐式主键的内部功能。此功能会在生成的名为DB_ROW_ID的列上自动生成名为GEN_CLUST_index的隐藏聚集索引。隐式主键是在创建没有Primary Key或UNIQUE Key的表时生成的,其中所有键列都分类:DataBase
2023年09月01日
免费MySQL在线数据库实验实例
 摘要:这家网站提供最新版本的MySQL免费实例,大家可以注册免费使用,再也不用自己创建虚拟机或购买1核1G的RDS了sqlpub.com 提供最新版本、甚至是开发者版本的 MySQL 服务器测试服务。 您可以轻易地 注册免费账号 测试您的应用。例如,您可以测试在MySQL版本升级后您的应用是否依然能够正常运行。 sqlpub.com 也是让您学习并熟悉新版本功能及操作的极佳资源。您将获得最大36000次/小时
摘要:这家网站提供最新版本的MySQL免费实例,大家可以注册免费使用,再也不用自己创建虚拟机或购买1核1G的RDS了sqlpub.com 提供最新版本、甚至是开发者版本的 MySQL 服务器测试服务。 您可以轻易地 注册免费账号 测试您的应用。例如,您可以测试在MySQL版本升级后您的应用是否依然能够正常运行。 sqlpub.com 也是让您学习并熟悉新版本功能及操作的极佳资源。您将获得最大36000次/小时分类:DataBase
2023年08月30日
MySQL 8 全新查看主从延迟的方法
 摘要:我们中的许多人,现在的的MySQL DBA使用SHOW REPLICA STATUS中的Seconds_Behind_Source来了解(异步)复制的状态和正确执行。请注意新的技术。我相信我们都用过旧的术语。然而,MySQL复制已经发展了很多,复制团队已经努力包含了许多关于MySQL可用的所有复制方式的有用信息。例如,我们添加了并行复制、组复制……所有这些信息都是从旧的SHOW REPLICA STATUS结果中看不到的。使
摘要:我们中的许多人,现在的的MySQL DBA使用SHOW REPLICA STATUS中的Seconds_Behind_Source来了解(异步)复制的状态和正确执行。请注意新的技术。我相信我们都用过旧的术语。然而,MySQL复制已经发展了很多,复制团队已经努力包含了许多关于MySQL可用的所有复制方式的有用信息。例如,我们添加了并行复制、组复制……所有这些信息都是从旧的SHOW REPLICA STATUS结果中看不到的。使分类:DataBase
2023年08月25日
MySQL官方建议跳过8.0.28-32版本,推荐使用MySQL 8.0.34
 摘要:2023年8月3日消息,MySQL副总裁Edwin Desouza近日指出MySQL 8.0.28-32 版本存在一些问题,建议用户使用8.0.33,或最好使用8.0.34。根据Desouza的建议,该推荐是基于一些在8.0.28-32版本中出现的问题。虽然这些问题可能不会对所有用户产生直接影响,但在某些特定情况下可能会造成数据丢失、性能下降或不一致的查询结果。为了确保用户的数据安全和数据库的稳定性,MySQL官方建议用
摘要:2023年8月3日消息,MySQL副总裁Edwin Desouza近日指出MySQL 8.0.28-32 版本存在一些问题,建议用户使用8.0.33,或最好使用8.0.34。根据Desouza的建议,该推荐是基于一些在8.0.28-32版本中出现的问题。虽然这些问题可能不会对所有用户产生直接影响,但在某些特定情况下可能会造成数据丢失、性能下降或不一致的查询结果。为了确保用户的数据安全和数据库的稳定性,MySQL官方建议用分类:DataBase
2023年08月18日
一次性搞懂MySQL如何存储emoji表情
 摘要:作为服务器开发人员,我们经常会遇到emoji存储问题。比如微信授权登录时,用户的昵称就有可能包含emoji表情。如果设置不当就有可能因为昵称字段无法写入数据库导致用户注册失败。MySQL存储emoji表情必须条件MySQL存储emoji表情的字段必须是utf8mb4编码格式注意这里是utf8mb4不是utf8,MySQL的utf8存储时用的是3个字节,但是emoji是4个字节,而utf8mb4也是4字节,所以字段才需要
摘要:作为服务器开发人员,我们经常会遇到emoji存储问题。比如微信授权登录时,用户的昵称就有可能包含emoji表情。如果设置不当就有可能因为昵称字段无法写入数据库导致用户注册失败。MySQL存储emoji表情必须条件MySQL存储emoji表情的字段必须是utf8mb4编码格式注意这里是utf8mb4不是utf8,MySQL的utf8存储时用的是3个字节,但是emoji是4个字节,而utf8mb4也是4字节,所以字段才需要分类:DataBase
2023年08月16日
Clickhouse SQL优化技巧
 摘要:1.使用分区clickhouse的表,走索引和非索引效率差距很大,在使用一个表进行查询时,必须限制索引字段。避免扫描全表确定索引分区字段,可以用show create table default.ods_user,查看本地表的建表语句,partition by 的字段就是分区字段。如果需要限制的时间和分区字段不是同一个字段时,可以扩大分区字段取数区间,然后再过滤2.distinct 和 group by优先使用group by,disti
摘要:1.使用分区clickhouse的表,走索引和非索引效率差距很大,在使用一个表进行查询时,必须限制索引字段。避免扫描全表确定索引分区字段,可以用show create table default.ods_user,查看本地表的建表语句,partition by 的字段就是分区字段。如果需要限制的时间和分区字段不是同一个字段时,可以扩大分区字段取数区间,然后再过滤2.distinct 和 group by优先使用group by,disti分类:DataBase
2023年08月16日
ClickHouse性能优化典藏
 摘要:一、 基础优化1 表优化1.1 数据类型建表时能用数值型或日期时间型表示的字段就不要用字符串,全String类型在以Hive为中心的数仓建设中常见,但ClickHouse环境不应受此影响。虽然ClickHouse底层将DateTime存储为时间戳Long类型,但不建议存储Long类型,因为DateTime不需要经过函数转换处理,执行效率高、可读性好。官方已经指出Nullable类型几乎总是会拖累性能,因为存储Nullabl
摘要:一、 基础优化1 表优化1.1 数据类型建表时能用数值型或日期时间型表示的字段就不要用字符串,全String类型在以Hive为中心的数仓建设中常见,但ClickHouse环境不应受此影响。虽然ClickHouse底层将DateTime存储为时间戳Long类型,但不建议存储Long类型,因为DateTime不需要经过函数转换处理,执行效率高、可读性好。官方已经指出Nullable类型几乎总是会拖累性能,因为存储Nullabl分类:DataBase
2023年08月15日
MySQL 2023-2024 Oracle ACE Program Members
 摘要:以下是Oracle官方博客公布的ACE清单,有没有熟悉的面孔呢Matthias JungElisa UsaiAaron FrancisDeepak VohraLixun PengSimon MuddTobias PetryTsubasa TanakaYe JinrongZhou ZhenxingCongratulations to all Oracle ACEs for MySQL !
摘要:以下是Oracle官方博客公布的ACE清单,有没有熟悉的面孔呢Matthias JungElisa UsaiAaron FrancisDeepak VohraLixun PengSimon MuddTobias PetryTsubasa TanakaYe JinrongZhou ZhenxingCongratulations to all Oracle ACEs for MySQL !分类:DataBase
2023年08月14日
B+ Tree算法演示网站
 摘要:昨天看互联网大佬的视频,发现一个图型化演示B+ Trees算法的网站,其它的算法演示也有https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html其它数据算法清单:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
摘要:昨天看互联网大佬的视频,发现一个图型化演示B+ Trees算法的网站,其它的算法演示也有https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html其它数据算法清单:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html分类:DataBase
2023年08月08日
MySQL索引长度(key_len)计算规则
 摘要:MySQL索引长度(key_len)计算 计算规则索引字段:没有设置 NOT NULL,则需要加 1 个字节。定长字段:tinyint 占 1 个字节、int 占 4个字节、bitint 占 8 个字节、date 占 3个字节、datetime 占 5 个字节、char(n) 占 n 个字节。变长字段:varchar (n) 占 n 个字符 + 2 个 字节。注意(字符和字节在不同编码之间的转换) 不同的字符集,一个字符占用的字节数不同lati
摘要:MySQL索引长度(key_len)计算 计算规则索引字段:没有设置 NOT NULL,则需要加 1 个字节。定长字段:tinyint 占 1 个字节、int 占 4个字节、bitint 占 8 个字节、date 占 3个字节、datetime 占 5 个字节、char(n) 占 n 个字节。变长字段:varchar (n) 占 n 个字符 + 2 个 字节。注意(字符和字节在不同编码之间的转换) 不同的字符集,一个字符占用的字节数不同lati分类:DataBase
2023年08月07日
DBA需要懂开发吗?
 摘要:DBA,指的是数据库管理员(Database Administrator)。DBA 是负责管理和维护数据库系统的专业人员,他们的工作涵盖了数据库系统的各个方面。传统上,DBA 主要专注于运维领域,DBA 是否需要懂开发呢?这是一个值得深思的问题。DBA的职责DBA 的职责包括安全加固、生产值班、工单处理、账号审计、例行巡检、容量管理、监控告警、部署交付、数据迁移、切换演练、上线变更、系统优化
摘要:DBA,指的是数据库管理员(Database Administrator)。DBA 是负责管理和维护数据库系统的专业人员,他们的工作涵盖了数据库系统的各个方面。传统上,DBA 主要专注于运维领域,DBA 是否需要懂开发呢?这是一个值得深思的问题。DBA的职责DBA 的职责包括安全加固、生产值班、工单处理、账号审计、例行巡检、容量管理、监控告警、部署交付、数据迁移、切换演练、上线变更、系统优化分类:DataBase
2023年07月29日
手把手教你在CentOS上使用docker安装MySQL8.0-亲测验证通过
 摘要:一、操作系统环境:[root@node10 ~]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node10 ~]# uname -aLinux node10 4.4.219-1.el7.elrepo.x86_64 #1 SMP Sun Apr 12 16:13:06 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux[root@node10 mysql]# docker -vDocker version 24.0.5, build ced0996二、安装docker使用具有管理员权限的账号进行安装,输入安装命
摘要:一、操作系统环境:[root@node10 ~]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)[root@node10 ~]# uname -aLinux node10 4.4.219-1.el7.elrepo.x86_64 #1 SMP Sun Apr 12 16:13:06 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux[root@node10 mysql]# docker -vDocker version 24.0.5, build ced0996二、安装docker使用具有管理员权限的账号进行安装,输入安装命分类:DataBase
2023年07月26日
MySQL 8.1.0二进制包安装配置详解
 摘要:官方多平台下载地址https://dev.mysql.com/downloads/mysql/Linux Generic(通用版)最新版64位下载地址 [8.1.0]https://dev.mysql.com/get/Downloads/MySQL-8.1/mysql-8.1.0-linux-glibc2.17-x86_64.tar.xz安装实践环境CentOS Linux release 7.6.1810 (Core) [root@node250 ~]# uname -r3.10.0-957.el7.x86_64下载[root@node250 ~]# wget https:/
摘要:官方多平台下载地址https://dev.mysql.com/downloads/mysql/Linux Generic(通用版)最新版64位下载地址 [8.1.0]https://dev.mysql.com/get/Downloads/MySQL-8.1/mysql-8.1.0-linux-glibc2.17-x86_64.tar.xz安装实践环境CentOS Linux release 7.6.1810 (Core) [root@node250 ~]# uname -r3.10.0-957.el7.x86_64下载[root@node250 ~]# wget https:/分类:DataBase
2023年07月26日
MySQL安装connection_control限制登录次数插件
 摘要:Connection-Control插件用来控制客户端在登录操作连续失败一定次数后的响应的延迟。可防止客户端暴力破解。一、查询插件是否安装mysql> show plugins;| CONNECTION_CONTROL | ACTIVE | AUDIT | connection_control.so | GPL &nb
摘要:Connection-Control插件用来控制客户端在登录操作连续失败一定次数后的响应的延迟。可防止客户端暴力破解。一、查询插件是否安装mysql> show plugins;| CONNECTION_CONTROL | ACTIVE | AUDIT | connection_control.so | GPL &nb分类:DataBase
2023年07月25日
MySQL可重复执行的ALTER SQL语句写法
 摘要:一、增删表语句1、以创建rsc_version表为例:--如果不存在则创建CREATE TABLE if not exists nsy_scm.`rsc_version` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `product_id` INT(11) NOT NULL DEFAULT '0', `process_id` INT(11) NOT NULL DEFAULT '0', `
摘要:一、增删表语句1、以创建rsc_version表为例:--如果不存在则创建CREATE TABLE if not exists nsy_scm.`rsc_version` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `product_id` INT(11) NOT NULL DEFAULT '0', `process_id` INT(11) NOT NULL DEFAULT '0', `分类:DataBase
2023年07月24日
MySQL MGR集群通过YUM小版本升级从8.0.25滚动升级到8.0.33
 摘要:线上MGR集群4节点服务已配置,运行的版本是8.0.25,现在将线上4台服务器实例滚动升级到8.0.33版本配置过程如下:查看现在的集群情况:mysql> select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+| CHANNEL
摘要:线上MGR集群4节点服务已配置,运行的版本是8.0.25,现在将线上4台服务器实例滚动升级到8.0.33版本配置过程如下:查看现在的集群情况:mysql> select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+| CHANNEL分类:DataBase
2023年07月19日
2023年7月18日正式发行新版本MySQL 8.1及MySQL 8.0.34
 摘要:千呼万唤始出来的新版本MySQL 8.1及MySQL 8.0.34于2023年7月18日正式发行。从此,MySQL将开启创新版和稳定版同时发行的阶段。MySQL 8.1是MySQL的首个创新版,该版本主要增加了如下功能 :捕捉EXPLAIN FORMAT=JSON 输出, 为 EXPLAIN FORMAT=JSON 增加 INTO 选项,可以将JSON格式的输出保存在一个用户变量中。保留客户端注释,MySQL8.1保留mysql客户端的注释,如果需要使用之前的行
摘要:千呼万唤始出来的新版本MySQL 8.1及MySQL 8.0.34于2023年7月18日正式发行。从此,MySQL将开启创新版和稳定版同时发行的阶段。MySQL 8.1是MySQL的首个创新版,该版本主要增加了如下功能 :捕捉EXPLAIN FORMAT=JSON 输出, 为 EXPLAIN FORMAT=JSON 增加 INTO 选项,可以将JSON格式的输出保存在一个用户变量中。保留客户端注释,MySQL8.1保留mysql客户端的注释,如果需要使用之前的行分类:DataBase
2023年07月19日
推出 MySQL 创新和长期支持(LTS)版本
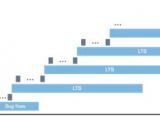 摘要:在甲骨文,我们不断寻找改进产品的方法,以更好地满足您的需求。我们很高兴推出 MySQL 创新和长期支持版本,这是 MySQL 版本控制模型的重要改进。MySQL 5.7 和以前版本的补丁版本专注于错误修复和安全补丁。在 MySQL 8.0 中发生了变化,补丁版本中的持续交付模型也包含新功能。这使得 MySQL 能够更频繁地向用户发布新功能,而不是每隔几年才能发布一次功能。但是,我们知道这种
摘要:在甲骨文,我们不断寻找改进产品的方法,以更好地满足您的需求。我们很高兴推出 MySQL 创新和长期支持版本,这是 MySQL 版本控制模型的重要改进。MySQL 5.7 和以前版本的补丁版本专注于错误修复和安全补丁。在 MySQL 8.0 中发生了变化,补丁版本中的持续交付模型也包含新功能。这使得 MySQL 能够更频繁地向用户发布新功能,而不是每隔几年才能发布一次功能。但是,我们知道这种分类:DataBase
2023年07月13日
MySQL 查看CPU占用高的SQL
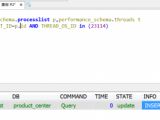 摘要:查找一下mysql的进程号:[root@mysql ~]# ps -ef | grep mysqlroot 7076 6919 0 09:43 pts/0 00:00:00 mysqlroot 7678 23069 1 10:15 pts/5 00:00:01 mysql product_centerroot 7710 7659 0 10:17 pts/2 00:00:00 grep --color=auto mysql
摘要:查找一下mysql的进程号:[root@mysql ~]# ps -ef | grep mysqlroot 7076 6919 0 09:43 pts/0 00:00:00 mysqlroot 7678 23069 1 10:15 pts/5 00:00:01 mysql product_centerroot 7710 7659 0 10:17 pts/2 00:00:00 grep --color=auto mysql分类:DataBase
2023年07月04日
静默升级Oracle 11g(从11.2.0.1升级到11.2.0.4)
 摘要:1、11.2.0.1环境(待升级数据库)SQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit ProductionPL/SQL Release 11.2.0.1.0 - ProductionCORE11.2.0.4.0ProductionTNS for Linux: Version 11.2.0.1.0 - ProductionNLSRTL Version 11
摘要:1、11.2.0.1环境(待升级数据库)SQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit ProductionPL/SQL Release 11.2.0.1.0 - ProductionCORE11.2.0.4.0ProductionTNS for Linux: Version 11.2.0.1.0 - ProductionNLSRTL Version 11分类:DataBase
关于我

Linux&MySQL数据库运维服务项目:
1.MySQL运维外包服务
2.MySQL高可用架构部署与调优
3.MySQL分库分表中间件部署与调优
4.MySQL数据库恢复及紧急救援服务
-> MySQL 误操作drop table/truncate table/drop database恢复
->MySQL 文件被误删除
->MySQL 数据库IB文件损坏等
->MySQL 备份损坏等
->MySQL 性能问题或疑难问题排查
->Linux 文件系统损坏、磁盘损坏等
5.MySQL数据库监控与报警
6.MySQL InnoDB Cluster集群
7.MySQL CDC数据同步工具
8.MySQL远程安装
9.VPN翻墙架设
10.Linux系统安全、监控、调优、应急故障处理
11.LANMPT网站平台环境安装配置,性能优化
12.详细报价以及其它服务内容请访问:www.ywsos.com
13、RHCE证书,CCNA证书,MySQL OCP,Oracle OCP证书信息查看
14、官方文档:
ORACLE_11G
MySQL_5.7
MySQL_8.0
PostgreSQL-13.1-CN
最火博文
 500台服务器搬迁,不容易啊
500台服务器搬迁,不容易啊- no active checks on server [127.0.0.1:10051]: host [zabbix.linuxidc.com] not found
- Docker FAQ FATA[0000] Error mounting devices cgroup: mountpoint for devices not found
- 查看mysql5.5 cmake安装时的编译参数
- 查看apache已安装的编译参数
- sudo权限集中管理与用户行为审计
- for和while常用方法
- /var/lock/subsys目录的作用
- Linux,25 岁生日快乐!
- MySQL,Oracle和PostgreSQL数据库体系架构详解
- 二进制包安装mysql5.5.32(免编译)
- Apache中RewriteRule和RewriteCond规则参数的详细介绍-域名跳转
- MySQL Proxy读写分离配置
- 全面解析Django的静态文件路径设置statics(settings.py)
- 关于世界上最伟大的Linux系统25个真相
最新评论
- [instance]
sql-mode = "STRICT_TRANS_TABLES"直接配置文件里加上这个试过了市可以的。
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- New topology could not be saved: Failed to parse topology file: yaml: unmarshal errors:
line 18: field instance.sql_mode not found in type spec.TiDBSpec
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- 大哥,5.1的esxi还能再共享一下吗?
- 匿名 @ VMware ESXi定制版(OEM ISO)资源下载(更新中)
- 没效果啊
- 匿名 @ 使用tab自动补全mysql命令
- 666
- 匿名 @ 500台服务器搬迁,不容易啊
- 111
- 匿名 @ 500台服务器搬迁,不容易啊
- 很好,
- ty-hongjy @ Flexviews-MySQL物化视图
- firewalld的防火墙的有吗?
- 匿名 @ Shadowsocks如何设置多外网IP