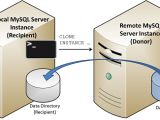
 摘要:环境配置:主机名 IP地址 角色 node222 172.16.1.222 数据源实例[donor]node223 172.16.1.223 空实例,数据目标实例[recipient]操作系统:CentOS Linux release 7.
摘要:环境配置:主机名 IP地址 角色 node222 172.16.1.222 数据源实例[donor]node223 172.16.1.223 空实例,数据目标实例[recipient]操作系统:CentOS Linux release 7.2023年07月02日
 MySQL8.0 Clone 数据库克隆案例详解
MySQL8.0 Clone 数据库克隆案例详解
摘要:环境配置:主机名 IP地址 角色 node222 172.16.1.222 数据源实例[donor]node223 172.16.1.223 空实例,数据目标实例[recipient]操作系统:CentOS Linux release 7.分类:DataBase
2023年06月27日
Oracle 11G truncate表后的快速恢复方法
 摘要:truncate表后的快速恢复方法在数据库运维中,相信大家都遇到过truncate表后,又需要找回数据的情况。但技术上因truncate表后不会产生日志记录和未生成回滚段,因此不能使用常规在线方式恢复,当然也不能用闪回恢复。常用的补救方法有:1、有备份的情况下可以用rman恢复,但是在生产业务库中,一般不能轻易停库,而且为了一张表而关库也会对其它正常的业务产生影响 ,所以这在时
摘要:truncate表后的快速恢复方法在数据库运维中,相信大家都遇到过truncate表后,又需要找回数据的情况。但技术上因truncate表后不会产生日志记录和未生成回滚段,因此不能使用常规在线方式恢复,当然也不能用闪回恢复。常用的补救方法有:1、有备份的情况下可以用rman恢复,但是在生产业务库中,一般不能轻易停库,而且为了一张表而关库也会对其它正常的业务产生影响 ,所以这在时分类:DataBase
2023年06月26日
ORACLE创建dblink的方法
 摘要:ORACLE创建dblink方法1、dblink的作用dblink数据库链接顾名思义就是数据库的链接,当我们要跨本地数据库,访问另外一个数据库表中的数据时,本地数据库中就必须要创建远程数据库的dblink,通过dblink本地数据库可以像访问本地数据库一样访问远程数据库表中的数据。2、查看是否有创建dblink的权限nsy_scm@ORCL> select * from user_sys_privs where privilege like upper('%D
摘要:ORACLE创建dblink方法1、dblink的作用dblink数据库链接顾名思义就是数据库的链接,当我们要跨本地数据库,访问另外一个数据库表中的数据时,本地数据库中就必须要创建远程数据库的dblink,通过dblink本地数据库可以像访问本地数据库一样访问远程数据库表中的数据。2、查看是否有创建dblink的权限nsy_scm@ORCL> select * from user_sys_privs where privilege like upper('%D分类:DataBase
2023年06月25日
Oracle 将于10月31日 终止支持 MySQL 5.7
 摘要:Oracle 将于 2023 年 10 月 31 日终止对其开发的开源关系数据库MySQL 5.7的支持。即将到来的生命周期终止日期意味着Oracle 将不再提供此版本数据库的更新,硅谷的一些知名人士广泛使用该版本的基于 Web 的应用程序。组织仍可根据需要继续使用此解决方案。距离 Oracle 的支持到期所剩时间不多,这重新引起了人们对五年前最初发布的MySQL 8.0的兴趣。Oracle 目前 MySQL 8.0&
摘要:Oracle 将于 2023 年 10 月 31 日终止对其开发的开源关系数据库MySQL 5.7的支持。即将到来的生命周期终止日期意味着Oracle 将不再提供此版本数据库的更新,硅谷的一些知名人士广泛使用该版本的基于 Web 的应用程序。组织仍可根据需要继续使用此解决方案。距离 Oracle 的支持到期所剩时间不多,这重新引起了人们对五年前最初发布的MySQL 8.0的兴趣。Oracle 目前 MySQL 8.0&分类:DataBase
2023年06月23日
oracle 11g R2(静默安装)for Centos7
 摘要:官方安装指南:Oracle® Database Quick Installation Guide环境准备Oracle安装首先请去官网下载软件包:Oracle 11.2.0.4.0下载地址https://updates.oracle.com/Orion/Services/download/p13390677_112040_Linux-x86-64_1of7.zip?aru=16716375&patch_file=p13390677_112040_Linux-x86-64_1of7.ziphttps://updates.oracle.com/Orion/Services/download/p13390677_112040_
摘要:官方安装指南:Oracle® Database Quick Installation Guide环境准备Oracle安装首先请去官网下载软件包:Oracle 11.2.0.4.0下载地址https://updates.oracle.com/Orion/Services/download/p13390677_112040_Linux-x86-64_1of7.zip?aru=16716375&patch_file=p13390677_112040_Linux-x86-64_1of7.ziphttps://updates.oracle.com/Orion/Services/download/p13390677_112040_分类:DataBase
2023年06月23日
实验验证:MySQL隔离级别与脏读、不可重复读、幻读
 摘要:实验验证:MySQL隔离级别与脏读、不可重复读、幻读查看、设置隔离级别因为MySQL默认隔离级别是 repeatable read,所以在测试其他隔离级别时,需要手动设置,下面是查看和设置隔离级别的方法。select @@transaction_isolation; -- 查看当前会话
摘要:实验验证:MySQL隔离级别与脏读、不可重复读、幻读查看、设置隔离级别因为MySQL默认隔离级别是 repeatable read,所以在测试其他隔离级别时,需要手动设置,下面是查看和设置隔离级别的方法。select @@transaction_isolation; -- 查看当前会话分类:DataBase
2023年06月19日
openGauss5.0企业版CentOS单节点安装-避坑指南
 摘要:一、安装环境CPU:2核内存:4G磁盘:20G操作系统:CentOS 7.9python版本:Python 3.6.8主机名:node111IP地址:172.16.1.111二、依赖包1、安装依赖包yum install -y libaio-devel flex bison ncurses-devel glibc-devel patch lsb_release readline-devel expect bzip2 ntp lsof2、检查是否已安装rpm -qa libaio-devel flex bison ncurses-devel glibc-devel patch lsb_release
摘要:一、安装环境CPU:2核内存:4G磁盘:20G操作系统:CentOS 7.9python版本:Python 3.6.8主机名:node111IP地址:172.16.1.111二、依赖包1、安装依赖包yum install -y libaio-devel flex bison ncurses-devel glibc-devel patch lsb_release readline-devel expect bzip2 ntp lsof2、检查是否已安装rpm -qa libaio-devel flex bison ncurses-devel glibc-devel patch lsb_release分类:DataBase
2023年06月15日
只有表结构和binlog二进制日志文件-如何恢复数据
 摘要:项目案例:这家客户有一个MySQL5.7的库,由于磁盘故障的原因,导致整个数据库目录文件损坏,但庆幸的是,BINLOG日志文件在另一个磁盘中,客户的需求是,想紧急恢复其中一个重要的表数据,其它的可以慢慢再做还原数据处理现在的问题是,手上有一个当时的binlog日志文件,也知道这张表的表结构,如何恢复数据?其实这种情况还是可以根据二进制日志进行恢复的,请听我慢慢讲来O(∩_
摘要:项目案例:这家客户有一个MySQL5.7的库,由于磁盘故障的原因,导致整个数据库目录文件损坏,但庆幸的是,BINLOG日志文件在另一个磁盘中,客户的需求是,想紧急恢复其中一个重要的表数据,其它的可以慢慢再做还原数据处理现在的问题是,手上有一个当时的binlog日志文件,也知道这张表的表结构,如何恢复数据?其实这种情况还是可以根据二进制日志进行恢复的,请听我慢慢讲来O(∩_分类:DataBase
2023年05月29日
PostgreSQL高可用工具-repmgr-自动故障转移
 摘要:集群安装配置:http://www.linuxmysql.com/14/2023/1194.htm通过在主,备库上定制failover脚本文件,利用repmgrd守护进程实现自动切换修改主备库上的repmgr.conf文件,添加故障自动切换参数node13:[root@node13 12]# cat repmgr.confnode_id=1node_name='node13'conninfo='host=node13 port=5432 dbname=repmgr user=repmgr password=123456'priority=3reconnect_attempts=6rec
摘要:集群安装配置:http://www.linuxmysql.com/14/2023/1194.htm通过在主,备库上定制failover脚本文件,利用repmgrd守护进程实现自动切换修改主备库上的repmgr.conf文件,添加故障自动切换参数node13:[root@node13 12]# cat repmgr.confnode_id=1node_name='node13'conninfo='host=node13 port=5432 dbname=repmgr user=repmgr password=123456'priority=3reconnect_attempts=6rec分类:DataBase
2023年05月29日
PostgreSQL高可用工具-repmgr-手动故障切换
 摘要:集群安装配置:http://www.linuxmysql.com/14/2023/1194.htm当主服务器发生宕机或服务异常不同用时,就需要让备服务器接管故障的主服务器,以确保整个repmgr集群对外可用,这时可以通过repmgr standby promotion完成备份服务器对主服务器的按管查看现在集群的状态:-bash-4.2$ repmgr cluster showID | Name | Role | Status | Upstream
摘要:集群安装配置:http://www.linuxmysql.com/14/2023/1194.htm当主服务器发生宕机或服务异常不同用时,就需要让备服务器接管故障的主服务器,以确保整个repmgr集群对外可用,这时可以通过repmgr standby promotion完成备份服务器对主服务器的按管查看现在集群的状态:-bash-4.2$ repmgr cluster showID | Name | Role | Status | Upstream分类:DataBase
2023年05月29日
PostgreSQL高可用工具-repmgr-集群部署
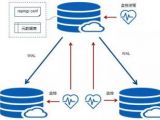 摘要:一主两从+见证节点-yum安装配置安装环境:服务 主机名 主机ip地址 操作系统 部署版本 安装路径主节点 node13 172.16.1.13 CentOS7.9 &nbs
摘要:一主两从+见证节点-yum安装配置安装环境:服务 主机名 主机ip地址 操作系统 部署版本 安装路径主节点 node13 172.16.1.13 CentOS7.9 &nbs分类:DataBase
2023年05月18日
like %abc% 这样的SQL能不能查,PG说可以,速度还很快
 摘要:LIKE和ILIKE是SQL的两个基本功能。人们在他们的应用程序中到处使用这些东西,因此从性能的角度来看这个主题是有意义的。PostgreSQL可以采取哪些措施来加快这些操作的速度,通常可以采取哪些措施要首先了解问题,其次才能获得更好的PostgreSQL数据库性能。创建示例数据在本文中,你将学到关于Gist和GIN索引的大部分知识。这两种索引类型都可以处理LIKE和ILIKE。这些索引类型的效
摘要:LIKE和ILIKE是SQL的两个基本功能。人们在他们的应用程序中到处使用这些东西,因此从性能的角度来看这个主题是有意义的。PostgreSQL可以采取哪些措施来加快这些操作的速度,通常可以采取哪些措施要首先了解问题,其次才能获得更好的PostgreSQL数据库性能。创建示例数据在本文中,你将学到关于Gist和GIN索引的大部分知识。这两种索引类型都可以处理LIKE和ILIKE。这些索引类型的效分类:DataBase
2023年05月12日
将数据库迁移到云之前需要考虑的一些事项
 摘要:在将数据库环境迁移到云之前,你应该首先考虑一些注意事项。云具有吹捧的一些优点的同时,也带来了一些风险和负面影响。让我们来看看其中一些事项。 首先,要考虑你是否会被供应商锁定。很多人选择开源数据库就是为了避免这一点。然而,有趣的事实是,实际上你可能在毫无意识的情况下被锁定。许多云供应商都有自己的数据库平台版本,例如MySQL、PostgreSQL、MongoDB 等。这些
摘要:在将数据库环境迁移到云之前,你应该首先考虑一些注意事项。云具有吹捧的一些优点的同时,也带来了一些风险和负面影响。让我们来看看其中一些事项。 首先,要考虑你是否会被供应商锁定。很多人选择开源数据库就是为了避免这一点。然而,有趣的事实是,实际上你可能在毫无意识的情况下被锁定。许多云供应商都有自己的数据库平台版本,例如MySQL、PostgreSQL、MongoDB 等。这些分类:DataBase
2023年04月19日
MySQL 8.0.17新特性-Redo日志归档功能
 摘要:功能作用:在备份操作进行期间,复制重做日志记录的备份实用程序有时可能无法跟上重做日志生成的步伐,从而导致由于这些记录被覆盖而丢失重做日志记录。当备份操作期间MySQL服务器有大量活动,并且重做日志文件存储介质的运行速度比备份存储介质快时,最常出现此问题。MySQL 8.0.17中引入的重做日志归档功能通过将重做日志记录顺序写入到除重做日志文件之外的归档文件来解决此问
摘要:功能作用:在备份操作进行期间,复制重做日志记录的备份实用程序有时可能无法跟上重做日志生成的步伐,从而导致由于这些记录被覆盖而丢失重做日志记录。当备份操作期间MySQL服务器有大量活动,并且重做日志文件存储介质的运行速度比备份存储介质快时,最常出现此问题。MySQL 8.0.17中引入的重做日志归档功能通过将重做日志记录顺序写入到除重做日志文件之外的归档文件来解决此问分类:DataBase
2023年02月23日
PostgreSQL pg_dumpall逻辑备份整个集群案例
 摘要:创建两个数据库并分别创建表和数据:postgres=# create database aaa;CREATE DATABASEpostgres=# create database bbb;CREATE DATABASEpostgres-# \c aaaYou are now connected to database "aaa" as user "postgres".create table a(id int);insert into a values (2);aaa=# \c bbbYou are now connected to database "bbb" as user "post
摘要:创建两个数据库并分别创建表和数据:postgres=# create database aaa;CREATE DATABASEpostgres=# create database bbb;CREATE DATABASEpostgres-# \c aaaYou are now connected to database "aaa" as user "postgres".create table a(id int);insert into a values (2);aaa=# \c bbbYou are now connected to database "bbb" as user "post分类:DataBase
2023年02月23日
PostgreSQL pg_dump逻辑备份案例
 摘要:单库-备份及恢复创建数据库以及表:postgres=# create database test;CREATE DATABASEpostgres=# \c testYou are now connected to database "test" as user "postgres".\c test;create table a(id int);insert into a values (2); test=# \d List of relationsSchema | Name | Type | Owner -----
摘要:单库-备份及恢复创建数据库以及表:postgres=# create database test;CREATE DATABASEpostgres=# \c testYou are now connected to database "test" as user "postgres".\c test;create table a(id int);insert into a values (2); test=# \d List of relationsSchema | Name | Type | Owner -----分类:DataBase
2023年02月23日
PostgreSQL pg_basebackup物理备份案例
 摘要:全量备份与恢复① 模拟环境:# 创建数据:create table t1(id int not null primary key,name varchar(20) not null);insert into t1 values(1,'zhnagsan'),(2,'lisi');配置postgresql.conf监听所有的ip:cat postgresql.conflisten_addresses = '*' # what IP address(es) to listen on;编辑pg_hba.conf添加允许主机以IP地址来连接并备份[po
摘要:全量备份与恢复① 模拟环境:# 创建数据:create table t1(id int not null primary key,name varchar(20) not null);insert into t1 values(1,'zhnagsan'),(2,'lisi');配置postgresql.conf监听所有的ip:cat postgresql.conflisten_addresses = '*' # what IP address(es) to listen on;编辑pg_hba.conf添加允许主机以IP地址来连接并备份[po分类:DataBase
2023年02月14日
MySQL数据实时同步至StarRocks集群配置详解
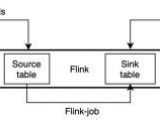 摘要:功能简介StarRocks 提供 Flink CDC connector、flink-connector-starrocks 和 StarRocks-migrate-tools(简称smt),实现 MySQL 数据实时同步至 StarRocks,满足业务实时场景的数据分析。基本原理通过 Flink CDC connector、flink-connector-starrocks 和 smt 可以实现 MySQL 数据的秒级同步至StarRocks。 MySQL 同步如图所示,Smt 可以根据 MySQL 和 StarRocks 的集群信息和表
摘要:功能简介StarRocks 提供 Flink CDC connector、flink-connector-starrocks 和 StarRocks-migrate-tools(简称smt),实现 MySQL 数据实时同步至 StarRocks,满足业务实时场景的数据分析。基本原理通过 Flink CDC connector、flink-connector-starrocks 和 smt 可以实现 MySQL 数据的秒级同步至StarRocks。 MySQL 同步如图所示,Smt 可以根据 MySQL 和 StarRocks 的集群信息和表分类:DataBase
2023年02月14日
StarRocks新一代极速全场景MPP数据库三节点集群安装配置详解
 摘要:环境:[root@node181 ~]# cat /etc/redhat-releaseCentOS Linux release 7.9.2009 (Core)[root@node181 ~]# uname -aLinux node181 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux集群节点:node181 172.16.8.181node131 172.16.8.131node132 172.16.8.132下载官方的tar包https://www.starrocks.io/download/c
摘要:环境:[root@node181 ~]# cat /etc/redhat-releaseCentOS Linux release 7.9.2009 (Core)[root@node181 ~]# uname -aLinux node181 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux集群节点:node181 172.16.8.181node131 172.16.8.131node132 172.16.8.132下载官方的tar包https://www.starrocks.io/download/c分类:DataBase
2023年02月07日
MySQL锁等待SQL收集shell脚本-全网最全-独一份
 摘要:有开启:performance_schema=on参数的情况下,可以用以下脚本收集:#!/bin/bashuser="root"password="123.123."logfile="/server/shell_scripts/mysql/innodb_lock_timeout_monitor/innodb_lock_timeout_monitor.log"while truedonum=`mysql -u${user} -p${password} -e "select count(*) from information_schema.innodb_lock_waits"
摘要:有开启:performance_schema=on参数的情况下,可以用以下脚本收集:#!/bin/bashuser="root"password="123.123."logfile="/server/shell_scripts/mysql/innodb_lock_timeout_monitor/innodb_lock_timeout_monitor.log"while truedonum=`mysql -u${user} -p${password} -e "select count(*) from information_schema.innodb_lock_waits"分类:DataBase
关于我

Linux&MySQL数据库运维服务项目:
1.MySQL运维外包服务
2.MySQL高可用架构部署与调优
3.MySQL分库分表中间件部署与调优
4.MySQL数据库恢复及紧急救援服务
-> MySQL 误操作drop table/truncate table/drop database恢复
->MySQL 文件被误删除
->MySQL 数据库IB文件损坏等
->MySQL 备份损坏等
->MySQL 性能问题或疑难问题排查
->Linux 文件系统损坏、磁盘损坏等
5.MySQL数据库监控与报警
6.MySQL InnoDB Cluster集群
7.MySQL CDC数据同步工具
8.MySQL远程安装
9.VPN翻墙架设
10.Linux系统安全、监控、调优、应急故障处理
11.LANMPT网站平台环境安装配置,性能优化
12.详细报价以及其它服务内容请访问:www.ywsos.com
13、RHCE证书,CCNA证书,MySQL OCP,Oracle OCP证书信息查看
14、官方文档:
ORACLE_11G
MySQL_5.7
MySQL_8.0
PostgreSQL-13.1-CN
最火博文
 500台服务器搬迁,不容易啊
500台服务器搬迁,不容易啊- no active checks on server [127.0.0.1:10051]: host [zabbix.linuxidc.com] not found
- Docker FAQ FATA[0000] Error mounting devices cgroup: mountpoint for devices not found
- 查看mysql5.5 cmake安装时的编译参数
- 查看apache已安装的编译参数
- sudo权限集中管理与用户行为审计
- for和while常用方法
- /var/lock/subsys目录的作用
- Linux,25 岁生日快乐!
- MySQL,Oracle和PostgreSQL数据库体系架构详解
- 二进制包安装mysql5.5.32(免编译)
- Apache中RewriteRule和RewriteCond规则参数的详细介绍-域名跳转
- MySQL Proxy读写分离配置
- 全面解析Django的静态文件路径设置statics(settings.py)
- 关于世界上最伟大的Linux系统25个真相
最新评论
- [instance]
sql-mode = "STRICT_TRANS_TABLES"直接配置文件里加上这个试过了市可以的。
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- New topology could not be saved: Failed to parse topology file: yaml: unmarshal errors:
line 18: field instance.sql_mode not found in type spec.TiDBSpec
- 匿名 @ [TiDB] 如何持久化配置sql_mode参数
- 大哥,5.1的esxi还能再共享一下吗?
- 匿名 @ VMware ESXi定制版(OEM ISO)资源下载(更新中)
- 没效果啊
- 匿名 @ 使用tab自动补全mysql命令
- 666
- 匿名 @ 500台服务器搬迁,不容易啊
- 111
- 匿名 @ 500台服务器搬迁,不容易啊
- 很好,
- ty-hongjy @ Flexviews-MySQL物化视图
- firewalld的防火墙的有吗?
- 匿名 @ Shadowsocks如何设置多外网IP