 给奔跑中的火车换轮子,58速运订单调度系统架构大解密[转]
给奔跑中的火车换轮子,58速运订单调度系统架构大解密[转]今天很荣幸给大家介绍 58 速运从艰苦创业到成为同城货运行业领头人的整个系统演进过程。

简单来说我们的业务是做同城货运,比如您去买一个大型家具,自己的家用车肯定是装不下的,这时你可能需要找路边的小型面包车或者金杯车来帮你搬运。
一般来讲,很容易遇到黑车,而且价格不标准,我们做的这个行业就是将这种传统的黑车行业进行线上化,在产品形态上可理解为滴滴打车的出租车版。
本次分享内容主要分为4个部分:
- 创业之初:快速迭代试错
- 高速发展:稳定、高效
- 智能时代:效率、精准
- 总结
创业之初:快速迭代试错
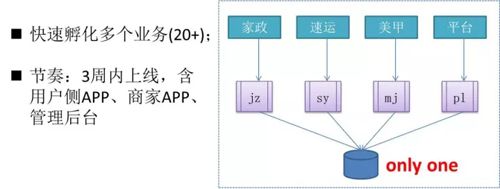
58 速运在 2014 年是作为 58 集团下 20 多个孵化业务中的其中一个,那个时期基本上是平均三个星期一个业务孵化上线,当时有 20 多个业务孵化同时进行。这个时间我们不断的试错,不断去寻找 58 同城新的增长点。
从上图中,大家可以看到,我们所有的服务都是基于一个数据库来运行的,这个系统之间只需要通过一些简单的 tag 标记就可以区分开业务,系统迭代非常快。
对于新孵化的业务,我们增加了一些简单的业务逻辑就能实现这个产品的快速上线,我们在两周内实现了速运用户、商家的 APP 以及后端的产品上线。
派单-石器时代

这时的系统架构是非常简单的,我们称之为“石器时代”,当时所有的订单调度的逻辑放在一个 Jar 包,然后通过 MQTT 服务将订单推送到司机的 APP 上。
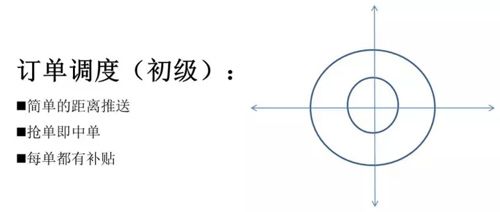
当时的订单调度(也是我们最初级的订单调度方案)是一个订单搜索附近的司机,然后由近到远的距离将订单推送出去,司机抢单后即中单。因为在创业阶段,我们需要吸引客户、司机,对于每单都会有补贴。
这个阶段面临的痛点如下:
- 系统不稳定,一个慢 SQL,全业务受影响,这里举个非常普遍的例子,其他业务线小伙伴在上线时,不小心写了一个慢 SQL,一个慢 SQL 就会把数据库的所有连接占满,导致所有的业务全部挂掉了,当时听到的最多的反馈是:什么情况,怎么你们又挂了。
- 多业务并存,订单表索引多,性能下降,当时有很多个业务在同时孵化,多业务并存,每一个业务都会根据它自己的业务需求在订单表中建立索引,结果索引越来越多,整体的性能也越来越差。
- 订单字段冗余,新增和修改字段非常痛苦。每个业务都有特殊的业务字段,单标数据量已经到达了千万级,每增加一个字段和修改一个字段,都需要耗费很长的时间,而且会造成锁库导致系统异常。
- 业务增长迅猛,数据库已成瓶颈,58 速运整体的订单增长非常迅速,在成立三个月以后,每天的单已达到了1 万+,系统性能已成为瓶颈。
针对以上痛点,我们做了第一次的技术引进――迁库、集群拆分。
第一次技术演进:迁库、集群解耦
为什么要迁库?谁痛谁知道!不想受到其他业务小伙伴的影响,就要做到解耦。
一个最简单的方案就是停服,把所有的服务停掉,然后把数据库抽离出来,相对来讲这是成本最简单的。
但是停服会产生的影响:
- 凌晨时间业务仍然有订单,会影响到用户访问。
- 需要给用户发公告。
- 停服迁移如果失败,无法向业务方解释,会丧失信任。
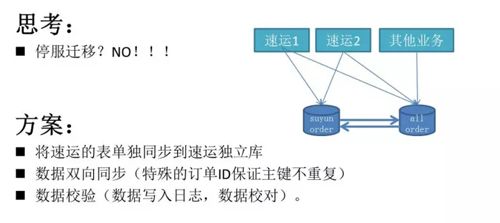
我们采用的方案:将订单表单独地拆离出来,放在单独的数据库里,两个数据库之间使用双向同步。
双向同步需要解决的问题:
- 主键冲突:速运的订单会标记一个比较特殊的标记 ID(如 80 开头标记为速运,其他业务都是 10 开头的),与其他的业务线区分开发,这样就可以保证它在双向同步时不会出现主键冲突的问题。
- 更新覆盖:update 的操作在同步的过程中因为时间差的问题可能存在写覆盖的情况,我们采用订单日志的记录,迁库完成后做数据的校验。
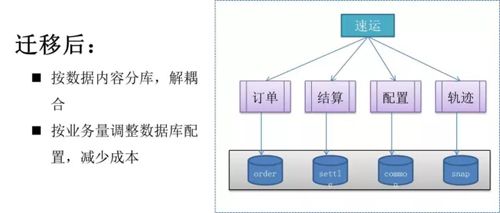
经过多次的迁移,将原有的数据库按照业务划分成了订单库、结算库、配置库和轨迹库等,每个数据库会根据业务量容量的大小来配置数据库物理机的内核、内存,减少成本。
高速发展:稳定、高效
2015 年我们进入了高速发展的阶段,市场上出现了蓝犀牛、1 号货的、云鸟的等多个强劲的竞争对手。各方都是争分夺秒,一个系统、功能,我需要抓紧把它给迭代上来,谁也不能比谁落后。
这个阶段我们存在的问题:
- 补贴大战,大量无效补贴,运营成本高,各大竞争对手投放大量的订单补贴(高达 30 元+),使得整体运营成本呈现水涨高船的趋势。
- 快速迭代多人维护一套工程,效率差,Bug 频发,最开始创业时团队只有几个人,工程都集中在几个集群中,后面扩大到 30 多个人时,大家都集中在这些集群上去开发,平均每天都要进行多次上线,遇到了个最核心、最痛点的问题,代码合并,合并代码就意味着出错的几率大大提升,当时 Bug 率很高。
- 业务高速发展,数据量急速增长,我们在 2015 年时,订单增长了好几倍,同时每个订单大概会推送给 50 多个司机,这个数据量级,数据量高速的增长。
- 运营分析需求越来越复杂,另外运营需要对现在的市场和用户进行分析,整体的运营需求分析逐渐复杂。
这时我们进行了第二次技术演进,我们称之为“进行了奔跑中的火车换轮子”,我们进行了服务化解耦;缓存、分库分表,提升系统性能;接入大数据平台,进行复杂需求的分析。
第二次技术演进:奔跑中的火车换轮子
派单-铁器时代
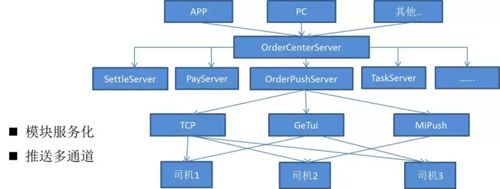
我们将所有的系统都按服务模块进行了拆分,比如说结算、充值、推送、司机任务等,现在大概已有 20+ 个服务,每个服务都有独立的数据库,有独立的负责人。
这样就可以做到我自己的代码我自己来写,别人都不允许去插手。
此外我们进行了推送的多通道化,从上图可以看到,我们针对每个司机选取了两种推送通道,同时我们也建议大家在做推送消息时采取这种方案。
拿小米的手机来说,“小米”推送通道的到达率是最高的,但小米的通道在华为的手机上,到达率不如“个推”的推送到达率高。
我们就会根据司机的机型来选取一个到达率最高的三方通道。同时在设计上不能有单点,假如说小米的通道出现了问题,那我们的服务就不可用了,司机接收不到订单,用户的需求就没法得到满足。
所以我们还有一个自研渠道 TCP 通道,这个 TCP 通道除了和我们三方通道做一个双通道保活外,它还可以做一些数据的上传。
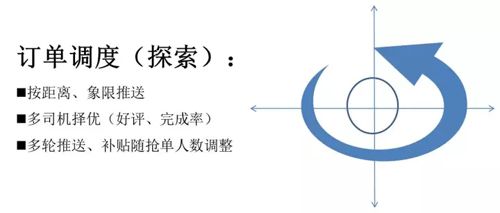
这时的订单调度,被称为探索阶段,初期的距离推送效果有限,谁抢到谁就中单,司机的服务质量我们没有办法去评判,补贴也是大众化的。
所以我们自己研究了一个按象限推送的方法:
- 首先我先推送一个很短的距离,比如说我先把一公里以内的所有司机都推送一遍,这时我是不给补贴的,当推完一公里以后没有人抢,或者是抢的人非常的少,我会按象限去推。
- 在第一个象限,我给一块钱补贴,如果没人抢,第二个象限给两块钱补贴,第三个象限给三块钱,这样逐步地去增加。
- 最后当司机抢了单,我们会根据司机的好评、完成率这些方面选择一个最优质的司机。
分库分表
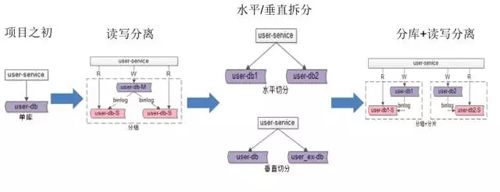
前面提到数据库性能已经成为瓶颈了,所以这里以一个用户服务给大家讲一下我们的分库分表是怎么做的:
- 业务初期,我们一个库可以完成支撑所有的访问。
- 随着数据量的增长,我们做了一些读写的分离,把一些读取 SQL 放在从库上,但这里给大家一个建议――订单状态的读取尽量不要在从库上读,网络一抖动,你的订单状态就很可能会出现不一致情况。
- 加上从库,当表的数据量达到千万级,查询的性能依然会下降,这样我们就需要去做水平拆分和垂直拆分。
水平拆分比较简单,大家也容易理解,而垂直拆分就是比如说我把一个用户 10 个最常用的属性放到一个组表里,把不常用的属性放到另外一张表里面去,这样可以减少 I/O 的操作,也可以提高整体的产品性能。
- 数据库水平拆分以后,再给拆分后的库增加从库。
在这里水平拆分要重点提一下,就是如果资源允许,水平拆分还是建议分库。
数据库的性能瓶颈也是会受到硬件设备和网络 IO 的影响,如果访问量持续增加,数据库还是会成为瓶颈。
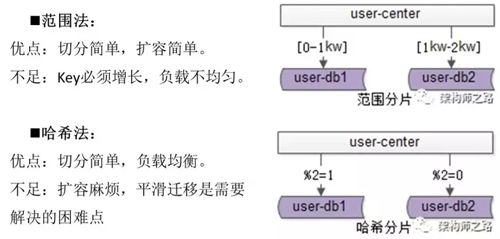
我们的水平拆分有两种方法:
范围法:用户 ID 在 1K 万以下的放到一个库,1K 万~2KW 以上的放到另外一个库,这样切分简单,扩容也方便,但是会存在数据库之间的负载不均匀。
哈希法:根据用户 ID 进行哈希运算,切分简单,整体负载比较均衡,平滑迁移可能是需要我们去解决的难点。
拆分后的问题:
- 部分查询变慢了:非 patition key 查询,需要遍历全部库,做完水平拆分以后,我们遇到了一个新的问题,实用 Patition key 水平拆分,非 patition key 查询需要扫库,性能反而变慢了。
- 运营需求无法实现:各种维度统计,没办法联表查询,运营小伙伴原来在单库的时候,因为复杂 SQL 跑的特别慢,导致无法统计特别情况,分完库以后,他连 Join 都用不了,更无法查询统计了。
问题分析,“任何脱离业务架构的设计都在耍流氓”:
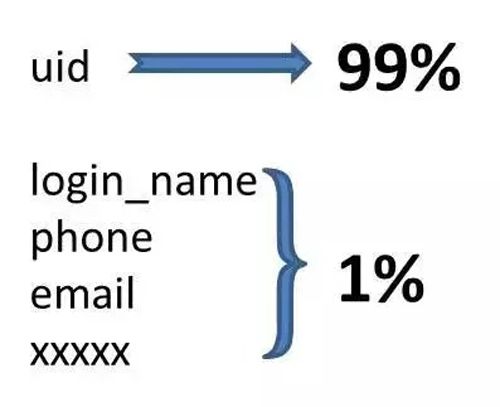
- 我们拿数据库的 Binlog 日志看了一下,根据用户 ID 的访问大概是占 99%,根据用户姓名、手机号、Email 的这些属性的查询大概只有在 1% 的量。
- 运营会根据年龄、性别、头像、登录时间、注册时间这些复杂的数据去做统计和分析。
前端解决方案:
- 索引表法:非 Patition key 与 uid 建立索引表,拿非 Patition key 和 uid 做一个索引表。
这样我直接通过这个表和 Patition key 进来后先去找一下 uid,这样就可以找到这个 uid 在哪个库,但是增加了一次数据库的查询。
- 缓存映射法:非 Patition key 与 uid 映射关系放入缓存,缓存命中率高,我们把 Patition key 与 uid 的映射关系放在缓存里面去,只会第一次比较慢,后面都会从缓存中取,而且这个缓存基本上不用淘汰。
- 非 Patition key 生成 uid,根据 Patition key 生成一个 uid,这个需要一定的生成技巧,同时这个可能有主键冲突的风险。
- 基因法,根据非 Patition key 的其中部分基因生成一个字段,如下图:

运营侧需求解决方案:
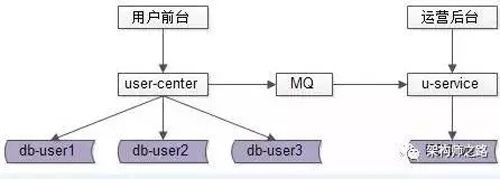
- 冗余后台库:通过 MQ/Canal 实时同步到后台库,通过 MQ 或者是 Canal 读取 MySQL 的 binlog,将几个前台的数据库实时地同步到后台库里去,后台库不对前台业务提供服务,仅供运营侧查询。
注意这个后台库是千万不能用于现场生产的,因为运营会在上面做一些复杂的慢查询,数据库的响应会非常慢。
- 外置搜索引擎:ES/Solr/XXXX,接入外键索引,如 ES/Solr 提供搜索服务。
- 大数据平台,使用大数据平台,通过 MySQL 的 binlog 和日志上报,将数据读取到大数据平台进行实时地分析,供运营查询。
到了 2016 年,竞争对手基本上已经被消灭了,58 速运已经成为行业的领头者了,如何使用更少的补贴获取最大化的收益?
我们有如下几点反思:
平台补贴是不是真的起到了作用,然后我们到底需要补多少钱才能帮助用户完成订单?
如何去尽量满足用户的需求?每个新用户进入平台是有成本的,一个用户的成本在几十甚至到一百块左右,如何满足用户的需求,让用户持续的留在平台中。
平台的司机良莠不齐,司机的收益应如何分配?
第三次技术演进:战斧项目
我们进行了第三次的技术引进,我们称之为战斧项目,项目的定义:精准、高效。
我们做了以下优化:
- 策略服务的细化
- 智能模型的接入
- 智能的分流框架
智能时代:效率、精准
智能模型训练
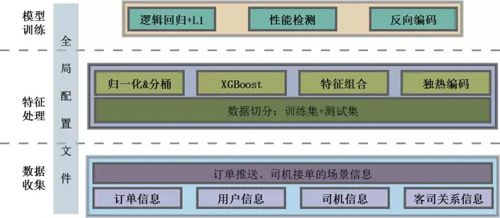
上图为智能模型训练图,首先我们会将订单信息、用户信息、司机信息、客司关系信息、订单总体推送、司机接单等场景信息统一上传到大数据平台。
通过这种归一化&分桶、XGBoost、特征组合、独热编码等将这些数据分析为特征数据。
针对分析出来的特征数据,我们需要对它进行训练,如:订单价格、订单距离等特征在整个订单派单中起到的权重。
因为特征很多,计算出来的权重可能并不是一个完美的解,只能说是近优、最优的一个解法,通过不断地迭代优化,最终训练出来最终的模型。
订单-模型运用
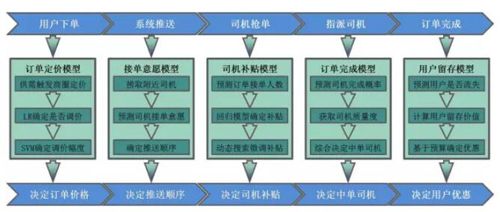
订单模型的运用:
- 下单阶段:在用户下单时,我们会采用这种用户订单定价的模型,观察这个订单所在的商圈的运力饱和度,如果司机少,而订单需求多,我们会进行一个订单的调价。
- 推送阶段:系统推送的过程中,会根据司机的接单意愿来捞取。有的司机喜欢高价格订单,有的司机喜欢短程订单,有的司机喜欢去中关村等。我们会根据订单与司机意愿的匹配程度进行优先推送的排序。
- 抢单阶段:先预估这个订单的接单人数,计算出来订单的价值,如果订单的价值高(价格高、地点好)、那么这个订单不会发放补贴了,同时会扣取司机的一些积分或优先抢单次数等。
- 如果订单价值比较低(价格低、偏远地区),会给这个订单适当地增加补贴,来确保订单的完成。
- 指派阶段:当司机抢完单以后,我们会根据所有司机历史完成订单的数据,取司机的质量,来决定哪个司机中单,保证订单尽可能完成。
- 订单完成阶段:订单完成了以后预测这个用户的流失概率,如果可能流失,会送一些券或者其他权益吸引用户留在平台。
派单-智能时代
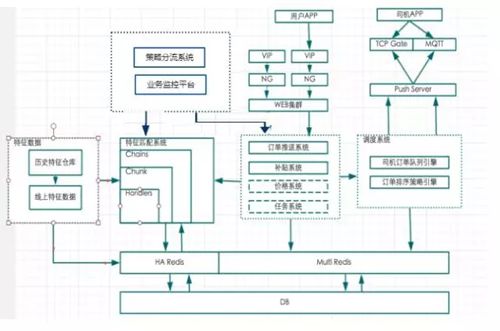
上图是智能派单时代的系统架构图。用户在下完单以后,订单会进入到我们整体的策略系统,它包含推送系统、补贴系统、价格系统、任务系统等。
然后通过特征匹配系统,计算出一个最优的订单调度解,将这个订单推送到司机的单队列引擎和订单的排序策略引擎,最终通过我们的推送服务将订单推送给司机。
策略分流+监测
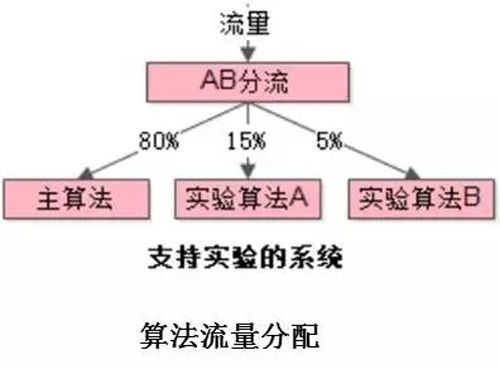
智能系统需要有不同的算法在线上实验,当我们一些新算法研发完成以后,肯定不能用 100% 的流量在线上进行验证算法的可行性,如果有问题,会对线上业务产生影响。
我们一般取 5% 或 10% 的流量在线上验证,根据用户手机号、设备码、用户属性等,以及取模、集合等方式。对线上算法验证时,如何实时的监测算法的效果,避免错误算法对线上业务造成的影响?
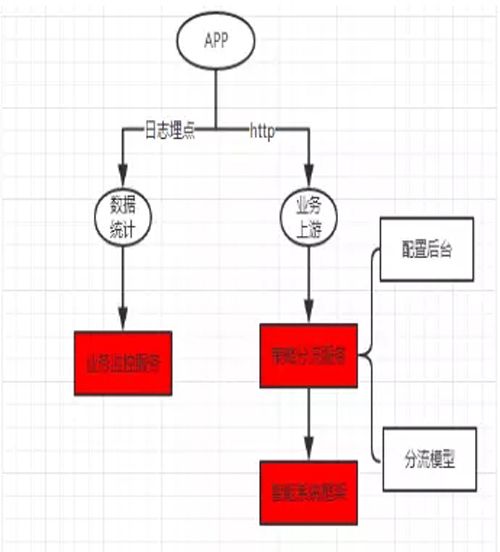
如上图所示,用户在 APP 中的每个步骤、运用了哪个算法,我们都会将用户的 ID、采用的算法 ID 通过日志上报到统计平台。业务监控平台会实时进行监控,对于出现异常的算法就自动关闭分流。
特征计算
特征数据中有 40 多万个特征,每个订单需要推送给很多个司机,需要进行上万次的运算,需要在几十毫秒内给出计算结果,如何保证计算的高性能呢?
我们采用的是这种阶段性事件驱动的计算方式来最大化提高并行计算的能力。
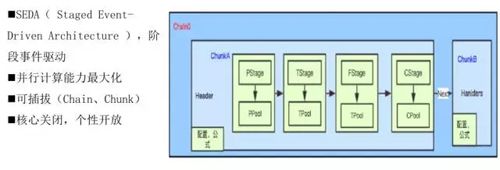
如图所示,这是我们的计算链,里面包含多个 Stage,包含准备阶段、转化阶段、取数阶段和计算阶段。
每一个阶段都有自己独立的线程池,根据每个阶段的特征设置核心线程数,同时整个计算链做到了可插拔的形式,方便业务调整。
利器-监控平台
监控可以说是整个架构演进过程中非常重要的部分:
- 再牛逼的算法,也需要稳定的系统来支撑。
- 业务出现异常,我们肯定要第一时间知晓。
- 提高问题排查效率,就是在挽救损失。
立体化监控
目前已经做到的监控包含:关键字、接口、流量、端口,JVM、CPU、线程、缓存、DB 所有的监控等等,同时还有服务治理,当服务节点发生异常,实时切换。
业务化的指标监控,渠道转化率、渠道取消率、渠道推送数量、异常订单数量等等,如果出现异常,第一时间预警。
调用跟踪系统
很多互联网公司都已经在使用调用跟踪系统,目的是需要看到 APP 发起的每个请求在整个 Service 后端走过的所有过程,效果如下图所示,可以监控到每一步所调用的服务和耗时。
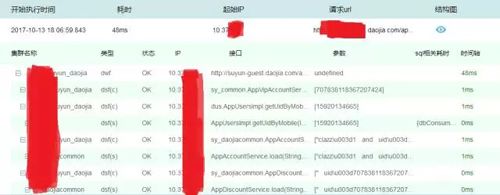
总结
最后给大家总结了 5 点经验:
- 不同的阶段采用不同的架构,技术的重点跟随业务转变。
- 订单的推送通道,建议使用双通道,保证推送的到达率。
- 数据库的水平拆分,在资源允许的情况下,强烈建议分库。
- 算法线上分流验证必须要有实时的监控和自动流量切换。
- 监控很重要,第一时间发现问题,减少影响。

胡显波,58 到家技术经理、58 速运后端架构总负责人。2014 年 7 月加入 58 到家,先后负责 58 到家 APP、58 小时工、58 美甲等,见证了 58 到家飞速发展。2014 年 11 月负责 58 速运整体业务,带领团队小伙伴支撑了速运业务日订单从 0~50W 的飞速增长。




