 centos6��jbd2����ռ�ô���IO����
centos6��jbd2����ռ�ô���IO�������칫˾��һ̨NFS����������IO�Ӹ߲��µ���� ��ͨ��iostat�鿴��ioʹ������80%���ϣ�ʱ������ֱ��IO���������NFS�ķ����쳣�������������������ɣ����ʹ��iotop�鿴������Ҫ��jbd2������д���µġ��������ͼiotop�Ľ����
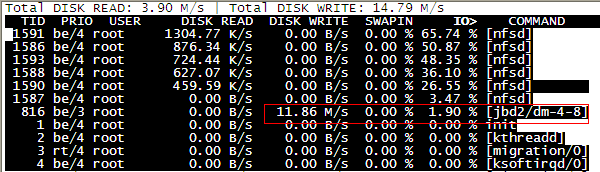
jbd2��ext4�ļ�ϵͳ��һ���֡�Ϊʲô��ʹ����δ˵�IO�������뵽����ext4д��־���������������ĵı䶯����д����£������������ϲ��Һ��֡�ext4�ļ�ϵͳ���ֹ�bug��bugԭ�������ǣ��ļ���д������ᵼ������һ��int�͵�ֵ������������������������ķ�Χ ���� ��ɸ�ֵ ���ͻᴥ����bug ������Ҫ�ﵽ��ֵ�������ף���Ҫ�����º�Ż���֡���ϸ��ԭ�����ٽ��ͣ��ؼ���ϸ����Ҳ��������������Ȥ�Ŀ��Բο�������ƪ��
http://blog.donghao.org/2013/03/20/��ext4��־��jbd2��bug/
http://www.udpwork.com/item/10217.html
��ubuntu��̳��Ҳ�������˷�ӳ�������⣺ http://ubuntuforums.org/showthread.php?t=2170496
�������ϼ����ط�����һ�����Եĵط�����������������ʱ�䶼����2013����Ѯ��ʱ�������ۺ�������Ϣ�ó��Ľ����������һ���ں�ext4�ļ�ϵͳ��bug��ʱ���Ѿ���ȥ������µ�ʱ�䡣��Ȼ��ʱ�����Ѿ������ṩ����ʱ������ ���ٷ�kernel��ҲӦ��������Ӧ�ĸ��¡����Դ�������������ȼ�Ϊ��
1��yum����kernel �������鿴�Ƿ���Ч�����ڴ�֮ǰ��Ҫ���ñ���ʹ�õ���������
2����װϵͳ��������ɺ����¹������ݷ�����
3����֤��ʱ�����Ŀ����ԡ�������������
������ʹ�õ�һ�� yum update����kernel���������� ������IO�ָ����� ��jbd2���̵�ʹ�ûָ�������ˮƽ
֮ǰ������jbd2����IO�ߵ����⣬ֱ�ӹص�����־�Ĺ��ܽ���ġ�д��һ�����£���д�IJ���ϸ������ּ��������⣬�������������¶�jbd2�����ݡ�
ʲôԭ��ᵼ��jbd2����IO�ߣ�
1. ������.
2. ϵͳbug����֪bug�ţ�Bug 39072 �C jbd2writes on disk every few seconds��
3. ��ʹû���������⡣��ext4����һ���¼���IJ���barrier����������֤�ļ�ϵͳ�������Եġ� [Barrier����]��https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/block/barrier.txt?id=09d60c701b64b509f328cac72970eb894f485b9e����
���ֵĬ����1�����Ǵ�״̬�������״̬�£���jbd2Ҳ�ǻᵼ�������½��ģ������������������Ϊ����ʧ�����ܱ�֤�ļ������ԡ�
���Ǹ�ѡ���⣬Ҫô��������Ҫô���ܲ
����������ܲ��ܺ��豸ӳ����ͬʱʹ�ã�Ҳ���ǣ������ʹ������������RAID����·�����̣������ֵ����Ч��
jbd2�Ǹ�ʲô��
1. TheJournalingBlockDevice (JBD) provides a filesystem-independent interfacefor filesystem journaling. ext3, ext4 and OCFS2 areknown to use JBD. OCFS2 starting fromLinux2.6.28[1] and ext4 use a fork ofJBD called JBD2.[2]
�ļ�ϵͳ����־���ܣ�jbd2��ext4�ļ�ϵͳ�汾��
����Ƿ����jbd2����
1. [root@7dgroup2~]# ps -ef|grep jbd2
2. root 267 2 0Aug21 ? 00:06:17 [jbd2/vda1-8]
3. root 2442822755 009:48 pts/0 00:00:00 grep --color=auto jbd2
4. [root@7dgroup2~]#
����ļ�ϵͳ�Ĺ���
1. [root@7dgroup2~]# dumpe2fs /dev/vda1 | grep has_journal
2. dumpe2fs 1.42.9 (28-Dec-2013)
3. Filesystem features: has_journalext_attr resize_inode dir_index filetype needs_recovery sparse_super large_file
4. [root@7dgroup2~]#
����has_journal��
��������
��ʹ��iotop����ʱ����������Ϣ���֡�
1. Total DISK READ: 46.15 M/s | Total DISK WRITE: 8.24 K/s
2. TID PRIO USER DISKREAD DISK WRITE SWAPIN IO> COMMAND
3. 4036 be/4 search 56.87 K/s 26.45 K/s 0.00 % 87.64 % [jbd2/dm-0-4]
�������һ
�ر���־���ܡ�
1. tune2fs -ojournal_data_writeback /dev/vda1
2. tune2fs -O"^has_journal" /dev/vda1
3. e2fsck -f /dev/vda1
���ʹ��tune2fsʱ����ʾdisk����mount������Ƿ�ϵͳ���£������ʹ��
1. fuser -km /home#ɱ������ʹ��/home�µĽ���
2. umount /dev/vda1#umount
֮����ʹ���������������Ƴ�has_journal��
���������
�����bug�Ļ������������ַ�ʽ���������Dz���bug�����ַ�ʽҲ������ˣ�����Ҫ���ж������������ԭ����ѡ����������
����ϵͳ�ںˡ�
1. yum updatekernel
���������
����Barrier��ͬʱ��commit��ֵ�������ʽ���Խ��barrier����������½������ǽ������ϵͳbug�����⡣
��commitֵ�������ļ�ϵͳ�ύ�������߽���barrier���ԣ� �����ļ�ϵͳ����Ϊ:
1. defaults,noatime,nodiratime,barrier=0,data=writeback,commit=60
Ȼ�����¹��ء�
1. mount -o remount,commit=60 /data
����barrier=0�ǽ���barrier����,commit=60�Ǽ����ύ������ �����ύ����ֻ�ܻ��⡣
���������
�������bug�����Ҳ������barrierʱ���ô˷�ʽ���⡣
�뾡�취����IO������IOѹ�������ַ�ʽҲ�ᵼ������ϵͳ��Դ�ò���ȥ������˵��mysql�а�syncbinlog�Ӵ�ͬʱ��innodbflushlogattrxcommit���ӡ� ����˵��Ӧ���м���IO�Ķ�д��
bug�ĸ�Դ
��֮ǰ�İ汾�г���������һ��ԭ����ext4�ļ�ϵͳ����bug�� ���bug���ֵıȽ����ˣ��ҿ�kerneltracker���������Ϣ��2011�꣬���������õ��ϰ汾���ҽ����������������û������������ֻ��������Ĺر���־���ܵĽ��������
bugԭ���ǣ� ����δ����У�
1. int __jbd2_log_start_commit(journal_t *journal, tid_t target)
2. {
3. /*
4. * Are we alreadydoing a recent enough commit?
5. */
6. if (!tid_geq(journal->j_commit_request,target)) {
7. /*
8. * We want a new commit: OK, mark the request and wakup the
9. * commit thread. We do _not_ do the commit ourselves.
10. */
11. journal->j_commit_request = target;
12. jbd_debug(1, "JBD:requesting commit %d/%dn",
13. journal->j_commit_request,
14. journal->j_commit_sequence);
15. wake_up(&journal->j_wait_commit);
16. return1;
17. }
18. return0;
19. }
�е�tid_geq�ĺ���������ʵ�ֵġ�
1. staticinlineint tid_geq(tid_t x, tid_t y)
2. {
3. intdifference = (x - y);
4. return (difference >= 0);
5. }
����jcommitrequestֵΪ2157483647����target��ֵΪ0������ȥ if (!tidgeq(journal->jcommit_request,target))����ж��Dz����ߵġ� ����unsigned int��x��ȥ0֮��תΪdifferenceʱ��difference�Ķ�����int�ͣ���ʱ�Ľ���Ƕ����أ���-2137483649�� Ϊʲô�أ���Ϊunsigned int���͵����ֵ��2147483647��
1. printf ("%d.n", 0x7FFFFFFF);
��2157483647 �C 0����������Ȼ����ˣ�����˸��������磬����Գ���������ӡ��
1. printf ("%d.n", 0x8FFFFFFFF);
����ͱ���ˣ�-1�� ����Ȥ�ģ������Լ�д����Դ����һ�¡�
1. #include<stdio.h>
2.
3. int main( void )
4. {
5. unsignedint x=2157483647;
6. unsignedint y=0;
7. int diff=0;
8. diff = x - y;
9. printf ("the diff is %ld.n", diff);
10. return0;
11. }
ִ��֮����ʲô�أ�
1. the diff is -2117515188..
�ɼ�����������£���Ϊ����ı�������if(!tidgeq(journal->jcommit_request, target))�ߵ��ˡ�
���unsigned int�ı�����jbd2��ÿ��transaction��tid��tid��һֱ���ӵģ���Ϊ����������������������tidgeq���ж��£���˼��2157483647���tid�Ѿ��ύ�ˣ�����1000�ŵ�transaction commit��������ִ����wakeup(&journal->jwaitcommit);������ִ��֮��ŷ��֣�ԭ����û�������е���������ϵͳ�ͷ��ˡ���trace jbd2�Ŀ��Կ���target��0�������ʵ���ϣ��ֵ�target��������0�����0����Ϊialloc.c�е�idatasynctidû����ȷ��ֵ������ʹ����Ĭ�ϵ�0�� idatasynctid���ڴ���inode����ext4iget()ʱ���µģ����Ӧ���ڴ�ijЩ�ļ���Ͳ��ٹرգ�ֻ��һֱ���£���ʱextent���Dz���ģ�ext4ʹ��extentȡ���˴�ͳ��blockӳ�䷽ʽ��������jcommit_request����jbd2��־���ύ���������ӣ�������������ֵ����ҵ�����е�һ��ʱ��֮����ָ�ֵ����������bug����Ļ������Կ�����������jbd2������̳�ʱ��ռ��99%��IO��
Ӱ��汾
�д������os�汾��ֻ������ʹ�ù��İ汾�еģ�
1. CentOS6.5-64bit
2. CentOS6.9-64bit
�ں˰汾��
1. 2.6.32-131.0.15.el6.x86_64




