 MySQL数据抽取CDC工具canal-1.1.5+kafka部署测试全记录
MySQL数据抽取CDC工具canal-1.1.5+kafka部署测试全记录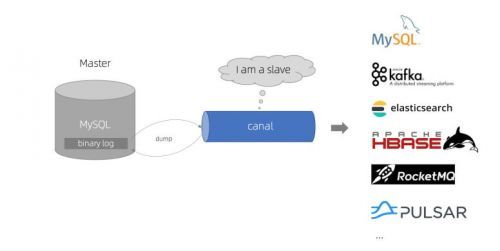
运行环境:
操作系统:
CentOS 7.9
canal相关组件:
zookeeper-3.4.14.tar.gz
kafka_2.13-2.4.0.tgz
canal.admin-1.1.5.tar.gz
canal.deployer-1.1.5.tar.gz
安装java运行环境:
yum install java-1.8.0-openjdk* -y
安装zookeeper
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
上传文件zookeeper-3.4.14.tar.gz 到/usr/local/目录下,并进行解压
tar xzvf zookeeper-3.4.14.tar.gz
创建对应的数据目录
mkdir -p /usr/local/zookeeper-3.4.14
mkdir -p /data/zookeeper
编辑zookeeper配置文件
cd /usr/local/zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg 编辑文件,修改成如下的参数
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper #只需要修改这个目录,其它的默认不变
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
保存并退出编辑
单节点的zk不用修改配置,可以直接启动。
当你看到Starting zookeeper ... STARTED,表示你的zookeeper服务已经启动成功了。我们可以用 jps 命令查询zookeeper启动是否正常(也可以用 ps -ef|grep zookeeper 命令查看),QuorumPeerMain这个进程就是zookeeper的进程。至此,zookeeper的单节点安装就成功了。
启动Zookeeper:
[root@node102 bin]# pwd
/usr/local/zookeeper-3.4.14/bin
[root@node102 bin]# /usr/local/zookeeper-3.4.14/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看监听的端口:
[root@node102 bin]# netstat -lntup | grep java
tcp6 0 0 :::42296 :::* LISTEN 8496/java
tcp6 0 0 :::2181 :::* LISTEN 8496/java
[root@node102 bin]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 8496 root 28u IPv6 46469 0t0 TCP *:eforward (LISTEN)
检查服务状态:
[root@node102 bin]# /usr/local/zookeeper-3.4.14/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: standalone
安装Kafka
Kafka是一个高性能分布式消息队列中间件,它的部署依赖于Zookeeper。笔者在此选用2.4.0并且Scala版本为2.13的安装包:
mkdir /usr/local/kafka
mkdir //usr/local/kafka/data
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -zxvf kafka_2.13-2.4.0.tgz
由于解压后/usr/local//kafka/kafka_2.13-2.4.0/config/server.properties配置中对应的zookeeper.connect=localhost:2181已经符合需要,不必修改,需要修改日志文件的目录log.dirs为/data/kafka/data。然后启动Kafka服务:
[root@node102 bin]# /usr/local/kafka_2.13-2.4.0/bin/kafka-server-start.sh /usr/local/kafka_2.13-2.4.0/config/server.properties
这样启动一旦退出控制台就会结束Kafka进程,可以添加-daemon参数用于控制Kafka进程后台不挂断运行。
[root@node102 bin]# /usr/local/kafka_2.13-2.4.0/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.13-2.4.0/config/server.properties
查看监听的端口:
[root@test-db-server config]# netstat -lntup | grep java
tcp6 0 0 :::33819 :::* LISTEN 28956/java
tcp6 0 0 :::9092 :::* LISTEN 28956/java
canal 安装
canal分为两个部分 admin 和server
admin就是一个web界面
server是后端的处理程序
首先安装canal-admin
MySQL数据库
MySQL数据库安装配置略
用户权限配置:
CREATE USER canal IDENTIFIED BY 'QWqw12!@';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
创建canal管理数据库:
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `canal_manager` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
GRANT ALL PRIVILEGES ON canal_manager.* TO 'canal'@'%';
创建一个测试数据库test:
CREATE DATABASE `test` CHARSET `utf8mb4` COLLATE `utf8mb4_unicode_ci`;
(1) 下载安装包
mkdir -pv /usr/local/canaladmin
cd /usr/local/soft
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.admin-1.1.5.tar.gz
(2) 解压
tar -xf canal.admin-1.1.5.tar.gz -C /usr/local/canaladmin
(3) 配置修改
cd canaladmin/
vim conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306 #管理端存放数据的连接地址,安装了mysql数据库的那台主机,用于存放canan-admin的元数据信息,配置信息
database: canal_manager #数据库名称
username: canal #数据库用户
password: QWqw12!@ #数据库密码
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
除了数据库连接其他的基本不用改
(4) 初始化元数据库
#连接数据库
mysql -hlocalhost -uroot -p
#登录msyql后,导入初始化sql
use canal_manager;
source conf/canal_manager.sql;
##注意使用具有远程功能的用户登录执行,或者将canal_manager.sql拷贝至mysql所在主机用root用户登录执行导入,或者使用第三方工具进行导入
(5) 启动
#启动
./bin/startup.sh
#查看日志
vi logs/admin.log
#关闭
./bin/stop.sh
查看端口号:
[root@test-db-server bin]# netstat -lntup | grep java
tcp 0 0 0.0.0.0:8089 0.0.0.0:* LISTEN 29671/java
canal server安装
(1) 下载安装包
mkdir -pv /usr/local/canalserver
cd /usr/local/soft
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
(2) 解压
tar -xf canal.deployer-1.1.5.tar.gz -C /usr/local/canalserver/
(3) 配置修改
vim canalserver/conf/canal_local.properties
# register ip
canal.register.ip = 172.16.1.102 #canal server注册IP 就是向admin 表明你是谁
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = ktp_canal #可以指定默认注册的集群名,如果不指定,默认注册为单机模式,除了这个基本不用改
注意:
#目前conf下会包含canal.properties/canal_local.properties两个文件,考虑历史版本兼容性,默认配置会以canal.properties为主,因为要启动为对接canal-admin模式,可以使用canal_local.properties文件覆盖canal.properties文件
cp canalserver/conf/canal.properties canalserver/conf/canal.properties_bak
cp canalserver/conf/canal_local.properties canalserver/conf/canal.properties
(4) 启动
#启动
./bin/startup.sh
#查看server日志
vi logs/canal/canal.log
#关闭
./bin/stop.sh
查看端口号:
[root@test-db-server bin]# netstat -lntup | grep java
tcp 0 0 0.0.0.0:11110 0.0.0.0:* LISTEN 29930/java
tcp 0 0 0.0.0.0:11111 0.0.0.0:* LISTEN 29930/java
tcp 0 0 0.0.0.0:11112 0.0.0.0:* LISTEN 29930/java
(5) 浏览器访问 http://172.16.1.102:8089 ,默认密码:admin/123456
登陆之后
首先配置 server管理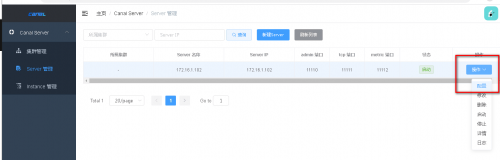
点选配置按钮
# tcp bind ip
canal.ip = 192.168.102.11
# register ip to zookeeper
canal.register.ip = 192.168.102.11
这个ip用来表明你的身份
我这里用到了zk和kafka 所以只配置了这两个
#单台配置:
canal.zkServers = 172.16.1.102:2181
#集群配置:
canal.zkServers = 192.168.102.11:2181,192.168.102.3:2181,192.168.102.2:2181
其余的配置没特殊情况不用改
#kafka.bootstrap.servers = 192.168.102.7:9092,192.168.102.3:9092,192.168.102.2:9092
其余的配置没特殊情况不用改
#1.1.5版本默认发消息到rabbitmq,下面配置将消息发送到kafka
canal.serverMode配置项指定为kafka,可选值有tcp、kafka和rocketmq(master分支或者最新的的v1.1.5-alpha-1版本,可以选用rabbitmq),默认是kafka。
canal.serverMode = kafka
canal.mq.servers配置需要指定为Kafka服务或者集群Broker的地址,这里配置为127.0.0.1:9092。
canal.mq.servers = 172.16.1.102:9092
canal.mq.servers在不同的canal.serverMode有不同的意义。
kafka模式下,指Kafka服务或者集群Broker的地址,也就是bootstrap.servers rocketmq模式下,指NameServer列表
rabbitmq模式下,指RabbitMQ服务的Host和Port
canal.mq.producerGroup = test #指定test组
保存后会自动载入
然后配置 Instance管理(数据源)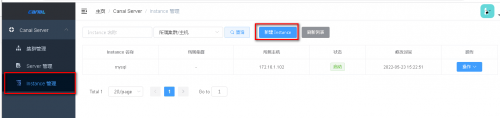
点击新建数据源。多数据源也直接在这里配置就行了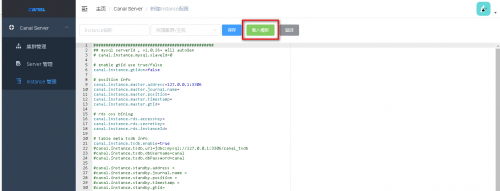
点击载入模板 会出现一个预制模板 。从这个模板开始修改
mysql数据源需要修改以下参数
canal.instance.master.address=172.16.1.102:3306
这是你需要连接的数据库地址 这栏目剩下的没有特殊情况不改
mysql的连接信息
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=QWqw12!@
canal.instance.defaultDatabaseName=test #指定需要解析的源库名
# table regex
canal.instance.filter.regex=.*\\..* #//所有库所有表
示例:
全库全表 canal.instance.filter.regex .*\\..* .*\\..*
指定库全表 canal.instance.filter.regex 库名\..* test\..*
单表 canal.instance.filter.regex 库名.表名 test.user
多规则组合使用 canal.instance.filter.regex 库名1\..*,库名2.表名1,库名3.表名2 (逗号分隔) test\..*,test2.user1,test3.user2 (逗号分隔)
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=test #将数据推送到kafka的 topic=test上
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0 #分区默认为0
其他的没有特殊情况也不用改
填入名称 选择好集群 保存
选择启动按钮 然后点击日志 查看连接结果 有什么报错排错就行了 ,基本就是一些密码不对权限不对之类的
数据测试:
在test数据库创建一个订单表,并且执行几个简单的DML:
use `test`;
CREATE TABLE `order`
(
id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
order_id VARCHAR(64) NOT NULL COMMENT '订单ID',
amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '订单金额',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
数据更新:
INSERT INTO `order`(order_id, amount) VALUES ('10086', 999);
UPDATE `order` SET amount = 10087 WHERE order_id = '10086';
DELETE FROM `order` WHERE order_id = '10086';
这个时候,可以利用Kafka的kafka-console-consumer或者Kafka Tools查看test这个topic的数据:
/usr/local/kafka_2.13-2.4.0/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic test --partition 0
具体的数据如下:
// test数据库建库脚本
{"data":null,"database":"`test`","es":1583143732000,"id":1,"isDdl":false,"mysqlType":null,"old":null,"pkNames":null,"sql":"CREATE DATABASE `test` CHARSET `utf8mb4` COLLATE `utf8mb4_unicode_ci`","sqlType":null,"table":"","ts":1583143930177,"type":"QUERY"}
// order表建表DDL
{"data":null,"database":"test","es":1583143957000,"id":2,"isDdl":true,"mysqlType":null,"old":null,"pkNames":null,"sql":"CREATE TABLE `order`\n(\n id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',\n order_id VARCHAR(64) NOT NULL COMMENT '订单ID',\n amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '订单金额',\n create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',\n UNIQUE uniq_order_id (`order_id`)\n) COMMENT '订单表'","sqlType":null,"table":"order","ts":1583143958045,"type":"CREATE"}
// INSERT
{"data":[{"id":"1","order_id":"10086","amount":"999.0","create_time":"2020-03-02 05:12:49"}],"database":"test","es":1583143969000,"id":3,"isDdl":false,"mysqlType":{"id":"BIGINT","order_id":"VARCHAR(64)","amount":"DECIMAL(10,2)","create_time":"DATETIME"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":-5,"order_id":12,"amount":3,"create_time":93},"table":"order","ts":1583143969460,"type":"INSERT"}
// UPDATE
{"data":[{"id":"1","order_id":"10086","amount":"10087.0","create_time":"2020-03-02 05:12:49"}],"database":"test","es":1583143974000,"id":4,"isDdl":false,"mysqlType":{"id":"BIGINT","order_id":"VARCHAR(64)","amount":"DECIMAL(10,2)","create_time":"DATETIME"},"old":[{"amount":"999.0"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"order_id":12,"amount":3,"create_time":93},"table":"order","ts":1583143974870,"type":"UPDATE"}
// DELETE
{"data":[{"id":"1","order_id":"10086","amount":"10087.0","create_time":"2020-03-02 05:12:49"}],"database":"test","es":1583143980000,"id":5,"isDdl":false,"mysqlType":{"id":"BIGINT","order_id":"VARCHAR(64)","amount":"DECIMAL(10,2)","create_time":"DATETIME"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":-5,"order_id":12,"amount":3,"create_time":93},"table":"order","ts":1583143981091,"type":"DELETE"}
Canal+kafka可以实现从mysql的binlog中抽取DML,DDL的数据到kafka,但缺点也很明显,无法实现全量数据同步以及全量+增量同步,后期可以考虑使用flink来实现更完整的CDC数据同步





