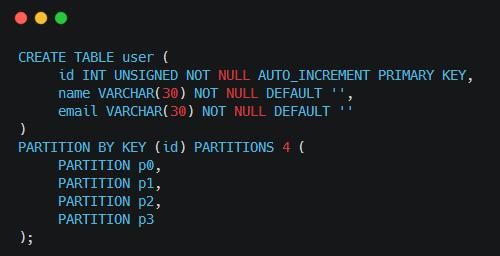
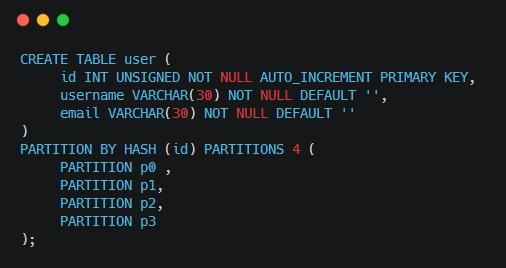
 MySQL�ķֱ������
MySQL�ķֱ������MySQL�ֱ������ǽ��������������MySQL���ܵ��µ����ַ�����
ʲô��MySQL�ֱ�
�ӱ�����˼�Ͽ���MySQL�ֱ����ǽ�һ�����ֳɶ���������ݺ����ݽṹ���п��ܻ�䡣MySQL�ֱ���Ϊ��ֱ�ֱ���ˮƽ�ֱ���
1����ֱ�ֱ�
��ֱ�ֱ��ǰ����е��ֶ������ֵģ�����ͼ��ʾ��
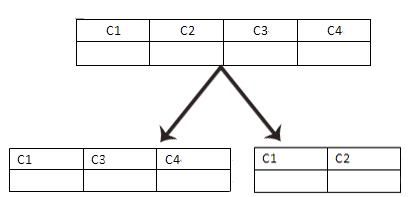
����ͼ�У����ǽ������ֲ���ͬһ�ű��е�C1��C2��C3��C4�ĸ��ֶδ�ֱ���ֵ��������С���һ�ű��зֲ�C1��C3��C4�����ֶΣ��ڶ��ű��зֲ�C1��C2�����ֶΡ���ֺ��������ͨ��C1�����ͬ���ֶι���������
2��ˮƽ�ֱ�
ˮƽ�ֱ��ǰ����еļ�¼�����ֵġ�����ͼ��ʾ��
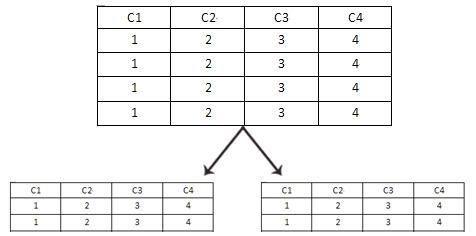
����ͼ�У����ǽ������ֲ���ͬһ�ű��е�������¼��ˮƽ��ֵ��������С���һ�ű��У��ֲ�������¼���ڶ��ű��У��ֲ�������¼��
3���ֱ�����
MySQL�ֱ��ȿ����Զ������Ҳ����ʹ��ҵ��ͨ�ù�������ʹ��merge�洢������ʵ�֡�
1���Զ������
�����û���ҵ��ı�ŷֱ��������û���ҵ������ձ��%n�����зֳ�n����
�������ڷֱ���������־��ͳ����ȵı�����������,�£��գ��ֱܷ���
2��ʹ��Merge�洢����
ʹ��Merge�洢����ʵ��MySQL�ֱ��Ƚ��ʺ���Щû�����ȿ��Ƿֱ����������ݵ����࣬�Ѿ����������ݲ�ѯ���������ʹ��Merge�洢����ʵ��MySQL�ֱ����Ա���Ĵ��롣ʹ��Mergeʵ��MySQL�ֱ�����������ʽ������
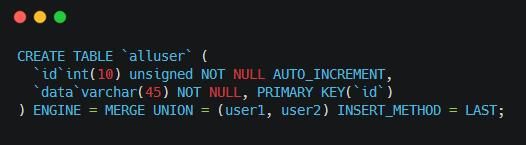
����ͼ�У�ENGINE = MERGE��ʾ��ʹ��merge���档����ENGINE = MRG_MyISAM��һ������˼��UNION = (user1, user2)��ʾ���ҽ���user1��user2����INSERT_METHOD = LAST��ʾ���뷽ʽ��0���������룬FIRST���뵽UNION�еĵ�һ������LAST���뵽UNION�е����һ������
ʹ��Merge�洢����ʵ��MySQL�ֱ����ֱ���Ľ�����Ϊ�������ӱ�������������һ�����ӣ����Ϸ�װ���ӱ���ʵ�������ݶ��Ǵ洢���ӱ��еġ�����ͼ��ʾ��
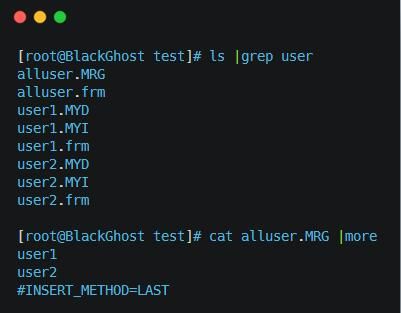
��ͼ�Ƕ�user������merge�ֱ��Ľ����alluser���ܱ���user1��user2�Ƿֱ���ÿһ���������Լ��ı��ṹ���ӱ����һ����������ݺ��������ܱ�û�б������ݺ��������ܱ�ֻ�����˷ֱ��Ĺ�ϵ���Լ��������ݵķ�ʽ��
4���ֱ���ѯ
���ڷֱ���IJ�ѯ��������Ȼ�����ϲ�ѯ����ͼ�Ȼ�������������ʹ��merge����ϲ����ݲ��ڴ˱��в�ѯ������һЩ������Ҫ�����洢��������ɣ������ⲿ����ʵ�ֶԷֱ��Ĺ������磺
- ��ֱ�ֱ���ʹ��join���ӡ�ˮƽ�ֱ���ʹ��union���ӡ�
- ����ʹ��Merge�洢����ʵ�ֵ�MySQL�ֱ�������ֱ�Ӳ�ѯ�ܱ���
5��ע������
1���ظ���¼ / �ظ�����
������Merge��ǰ���ֱ�t1 / t2�Ѿ����ڣ�����t1 / t2�д����ظ���¼����ѯʱ�����������¼����Ŀ�ͻ᷵�ء���˼����ֻ����ʾһ����¼��ͬʱ���ᱨ����������Merge����insert / updateʱ�������ظ������������ʾ����MERGE��ֻ�Խ���֮��IJ�������
2�����ɾ��һ���ֱ�
����ֱ��ɾ��һ���ֱ����������ƻ�Merge������ȷ�ķ����ǣ�
- alter table t ENGINE = MRG_MyISAM UNION = (t1) INSERT_METHOD = LAST��
- drop table t1��
3����ɾMerge�ܱ�
��ɾMerge�����Dz���������ݶ�ʧ�ģ�ֻ�����´����ܱ���
ʲô��MySQL����
�ӱ�����˼����MySQL�������ǽ�һ�ű������ݷֳɶ���洢���飬�����ݽṹ���䡣���⣬��Щ�洢����ȿ�����ͬһ�������ϣ�Ҳ�����ڲ�ͬ�Ĵ����ϡ�����ͼ��ʾ��
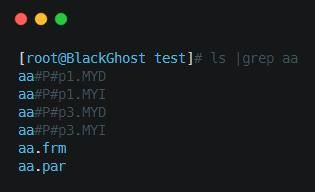
��ͼ�ǶԱ�aa���з��������ϵ��ļ��ֲ�����ͼ�����ǿ��Կ�����������aa�������ݽṹû�з����仯�������ݺ������洢��λ����ԭ����һ����������������⣬�����һ��.par�ļ�����.par�ļ�������Կ�������¼�����ű��ķ�����Ϣ��
1����������
MySQL��5.1.3��ʼ֧��Partition�������ʹ������������ȷ����İ汾�Ƿ�֧��Partition��
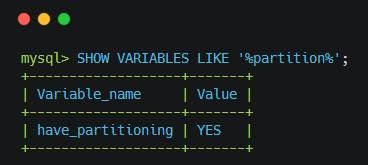
MySQL֧�ֵķ������Ͱ���Range��List��Hash��Key������Range�Ƚϳ��ã�
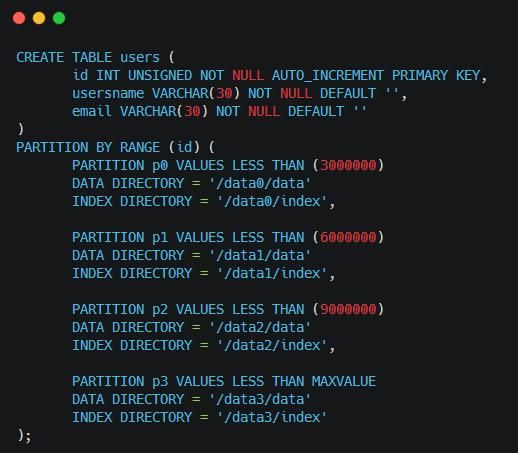
1��Range����Χ�� �C ����ģʽ����DBA�����ݻ��ֲ�ͬ��Χ������DBA���Խ�һ����ͨ����ݻ��ֳ�����������80�����1980's�������ݣ�90�����1990's���������Լ��κ���2000�꣨����2000�꣩������ݡ����£�
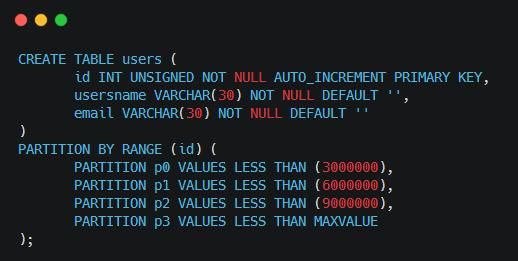
��������û����ֳ�4����������ÿ300������¼Ϊ���ޣ�ÿ�����������Լ����������ݡ������ļ��Ĵ��Ŀ¼��
2��List��Ԥ�����б��� �C ����ģʽ����ϵͳͨ��DBA������б���ֵ����Ӧ�������ݽ��зָ���磺DBA�����û������ͽ��з�����
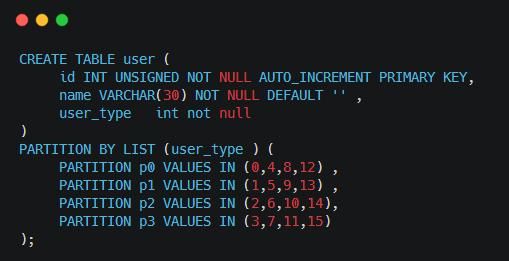
3��Key����ֵ�� �C ����Hashģʽ��һ�����죬�����Hash Key��MySQLϵͳ�����ġ�
4��Hash����ϣ�� �C ����ģʽ����DBAͨ���Ա���һ�������е�Hash Key���м��㣬���ͨ�����Hash�벻ͬ��ֵ��Ӧ������������з�����������DBA���Խ���һ���Ա��������з����ı���
2��ע������
1������ÿһ�ַ�����ʽ�������Խ���Щ�������ڵ��������̷ֿ���ȫ����������ߴ���IO�����������£�
��ͼ���Ƕ�Range����Χ���������ͽ��������ռ�ķ��������
2��������Ȼ��ˬ����Ŀǰ��ʵ�ֻ��кܶ����ƣ�
- ��������Ψһ����������������ֶΣ���PRIMARY KEY(i��created)��
- �ܶ�ʱ��ʹ���˷����Ͳ�Ҫ��ʹ���������������Ӱ�����ܡ�
- ֻ��ͨ��int���͵��ֶλ��߷���int���͵ı���ʽ��������ͨ��ʹ��YEAR��TO_DAYS�Ⱥ�����
- ÿ�������1024�������������������Ƶ���չ���������ҹ���ʹ�÷������������Ĵ���ϵͳ�ڴ档
- ���÷����ı���֧���������ص�Լ��������ͨ��������ʵ�֡�
MySQL�ֱ��ͷ�������ͬ
�������mysql���Ըߣ��ڸ߲���״̬�¶���һ�����õı��֡�
�ֱ��ͷ�����ì�ܣ��������ϵģ�������Щ������������ұ����ݱȽ϶�ı������ǿ��Բ�ȡ�ֱ��ͷ�����ϵķ�ʽ�����merge���ֱַ���ʽ�����ܺͷ�����ϵĻ��������������ķֱ��ԣ��������������DZ����ݺܶ�ı������ǿ��Բ�ȡ�����ķ�ʽ�ȡ�
�ֱ������DZȽ��鷳�ģ���Ҫ�ֶ�ȥ�����ӱ���app����˶�дʱ����Ҫ�����ӱ���������merge��һЩ����ҲҪ�����ӱ��������ӱ����union��ϵ��
����������ڷֱ����������㣬����Ҫ�����ӱ���




